Research
Our research is multidisciplinary and covers several domains of applications. The common denominator of our team is the use and development of advanced machine learning and data acquisition methods applied to the experimental sciences. In particular we focus on the use of deep learning and representation learning in order to answer questions about ethology, human cognition and the environment.
Bioacoustics

Halting the rapid loss of marine biodiversity in light of climate change, and pollution issues is one of the global sustainability challenges of the decade. The importance of environmental monitoring, enabling effective measures is increasingly recognized. Although a variety of methods exist to survey local species richness, they have been characterized as costly, invasive and limited in space and time, highlighting the need to improve environmental data acquisition techniques. To that end, more recent research indicates the potential effectiveness of the use of (bio) acoustic signals for studying the evolution of population dynamics and modelling the variations species richness.

The DYNI team conducts research aimed at detection, clustering, classification and indexing bioacoustic big data in various ecosystems (primarily marine), space and time scales, in order to reveal information on the complex sensori-motor loop and the health of an ecosystem, revealing anthropic impacts or new biodiversity insights.
DYNI continues to install its bioacoustic surveillance equipment throughout the world including, France, Canada, Caribbean islands, Russia, Madagascar etc. Its present projects study different problematics like the influence of marine traffic on marine mammals.
Speech and hearing
We focus on several aspects of human vocal interactive behaviour and more particularly speech. Some of the research problems that we tackle are:

- modelling speech perception,
- robust automatic speech recognition,
- multimodal speech (e.g. audio-visual),
- multichannel speech processing, and
- speech enhancement.
We are also interested in clinical applications of speech technology and research on hearing aid devices.
Currently we are focusing on two specific problems: microscopic intelligibility modeling and unsupervised speech learning.
Some of our research questions in microscopic intelligibility modeling include: (i) can we employ data-driven techniques to predict individual listener behaviors at a sub-lexical level? and (ii) can data-driven models help us better understand and validate our knowledge about the mechanisms involved in human speech perception and production? To this end we try to make machines listen more like humans in speech recognition tasks and interpret the resulting models to compare them to existing human hearing models.
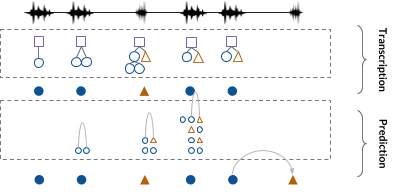
We are also interested in the difficult task of unsupervised speech learning. Can we learn to transcribe speech of a language for which we do not have textual representation? Acoustic unit discovery (AUD) and linguistic unit discovery (LUD) are challenging tasks that have not received the same attention as their supervised counterparts. Yet the problems are interesting from both an engineering and a scientific point of view. Unsupervised speech learning closely relates to research on language acquisition modelling and language evolution, with ties to categorical perception and grammar induction. From an application point of view, work on this problem not only benefits speech processing of under-represented languages, but also the generic problem of pattern and structure discovery in time-series data.
Astrophysics
The research conducted at DYNI also considers the combination of machine learning with astrophysical applications. Some of these applications include:
- the detection, segmentation, and tracking of structures of the solar atmosphere using multi-spectral solar images,
- the study and modelling of the temporal evolution of these structures, and their relation with events of solar activity,
- detection of solar radio bursts that are signatures of solar activity events,
- techniques of astrophysical data-cleaning to aid in other down-stream tasks,
- characterisation of galaxy morphology, with a focus on low surface brightness structures that originated from past collisions of galaxies.
Currently, we are focusing on two specific problems: 1) understanding the underlying mechanisms of, and predicting, the events of solar activity, and 2) detecting the indices of past galactic collisions in order to study the evolutionary history of galaxies.

The first research theme concerns itself with the activity of the Sun, those events (e.g. flares, coronal mass ejections (CME)) are dynamical phenomena that may have strong impacts on the solar-terrestrial environment. Events of solar activity seem to be strongly associated with the evolution of solar structures (e.g. active regions, filaments), which are objects of the solar atmosphere that differ from the “quiet Sun” and which appear, evolve, and disappear over a period of days to months. The exact mechanisms of solar activity, and the links between solar structures and activity events, are still ill-understood. We aim to develop novel and physics-based machine learning methods for enabling the first ever big-data analysis of solar structures and solar activity.
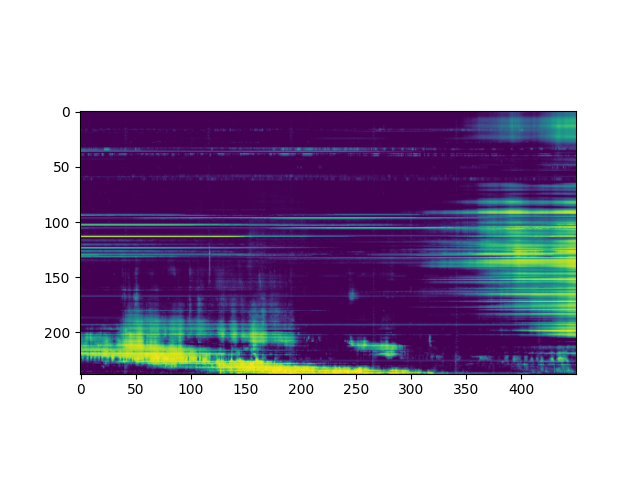
In an ANR JCJC-funded project, the detection of solar structures on various levels of the solar surface are combined in order to study their temporal evolutions and behaviours, and to discover their levels of relationship with events of solar activity. This project is a partnership with Observatoire de Paris.
In a second project, we develop physics-informed machine learning methods to detect solar radio bursts, which are signatures of solar activity events in radio spectrograms. This work is also a partnership with Observatoire de Paris, as well as with the Space Environment Laboratory (NICT, Japan) through the recent support of the French-Japanese “Exploration Japon” program.
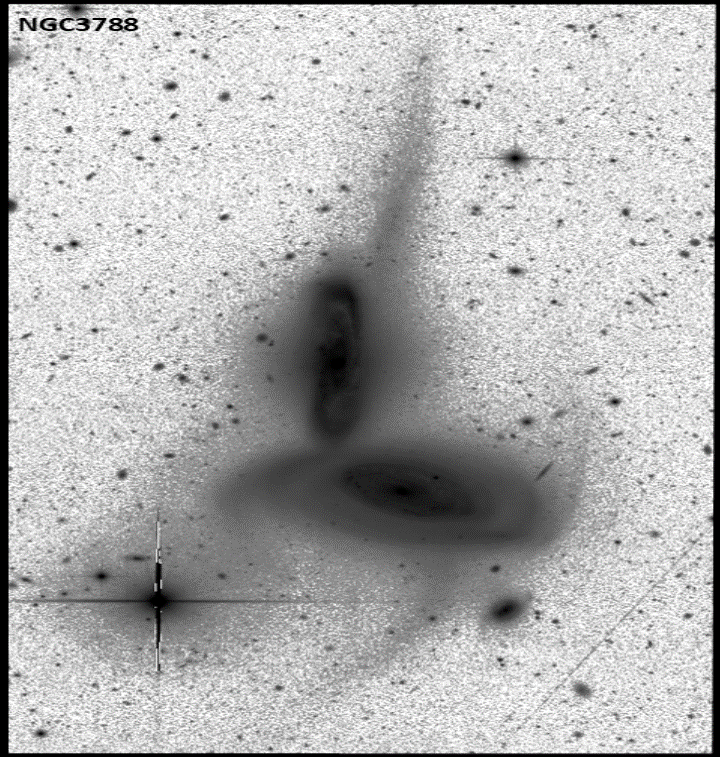
The second main research theme develops new deep learning techniques to finely characterise the morphology of galaxies from large datasets of deep optical imaging. The astrophysics community faces a deluge of images that cannot be fully exploited by traditional manual and semi-automated analysis. We address this situation by developing fully automated and high precision visual analysis algorithms. They aim to identify the diffuse tidal stellar features that surround galaxies and that bring a testimony on past galaxy collisions. Because of their low surface brightness and the presence of multiple contaminants, they are particularly difficult to isolate with classical IA techniques. New algorithms are being designed to address the specific challenges of these astrophysics data by integrating prior physics knowledge into the design of deep neural networks. This work is a partnership with Observatoire de Strasbourg and Brookhaven National Laboratory (USA). It is supported by a funding from the “Sciences pour l’IA, l’IA pour les sciences” program of CNRS MITI.
Underwater robotics
In collaboration with IFREMER and led by PhD candidate Clementin Boittiaux we are working on using data-driven techniques, to enhance the autonomy of unmaned underwater vehicles. We have been advancing the field of visual localization methods with the following contributions: 1) a novel loss function between 2 camera poses, 2) a dataset for long-term visual localisation in the deep sea, and 3) a method of underwater color restoration that leverages scene structure.
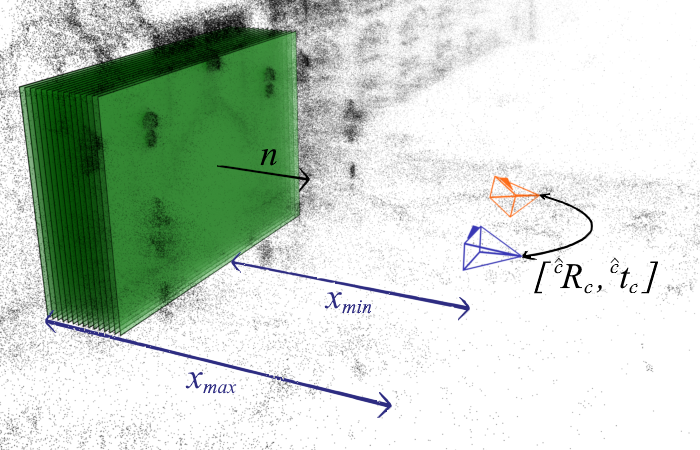
Some recent visual-based relocalization algorithms rely on deep learning methods to perform camera pose regression from image data. They are based on loss functions that embed the error between two poses to perform deep learning based camera pose regression. Existing loss functions are either difficult-to-tune multi-objective functions or present unstable reprojection errors that rely on ground-truth 3D scene points and require a costly two-step training. We have proposed a novel loss function which is based on a multiplane homography integration. This new function does not require prior initialization and only depends on physically interpretable hyperparameters. Furthermore, the experiments carried out on a well established relocalization benchmark show that it minimizes best the mean square reprojection error during training when compared with existing loss functions.

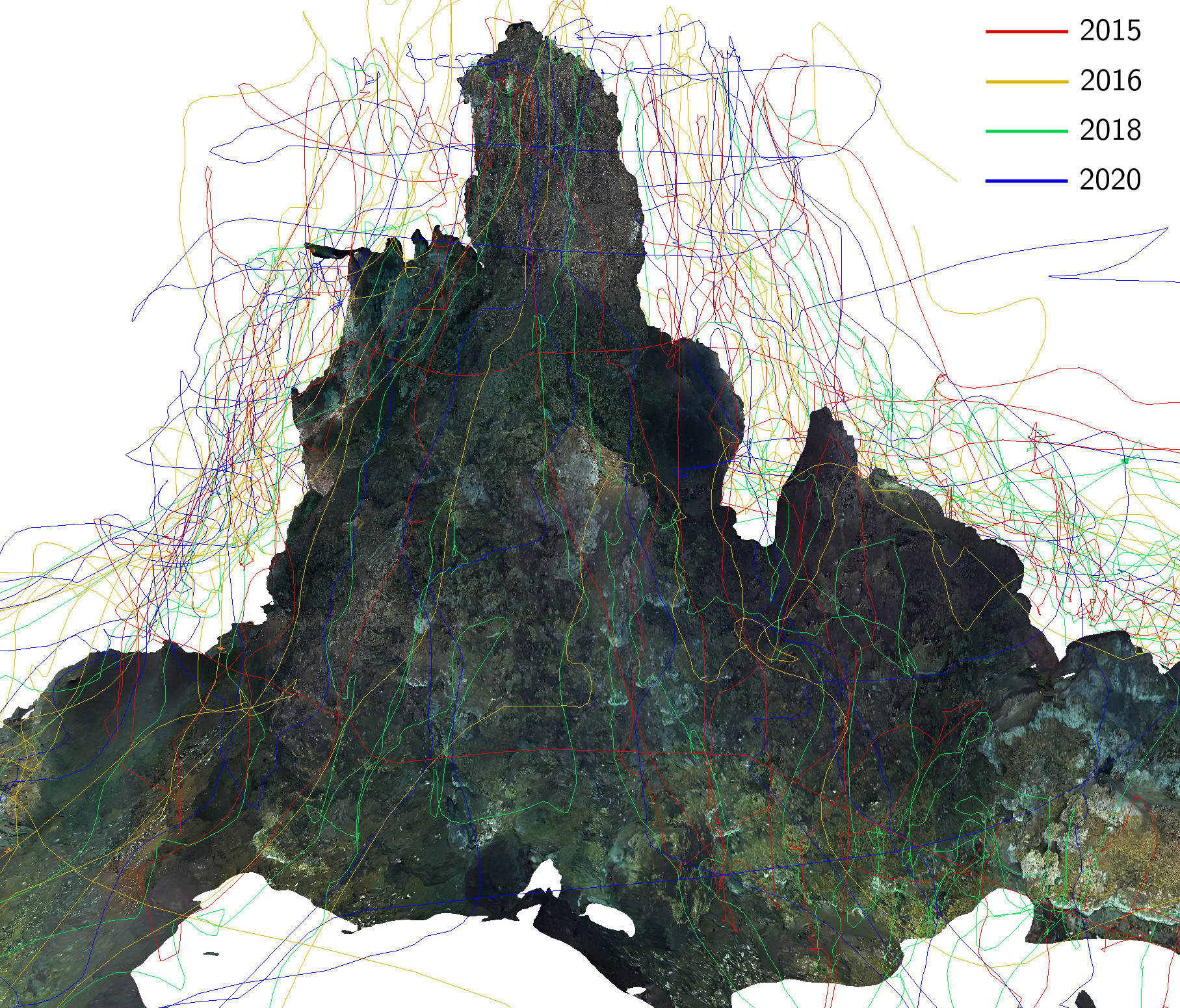

Visual localization plays an important role in the positioning and navigation of robotics systems within previously visited environments. When visits occur over long periods of time, changes in the environment related to seasons or day-night cycles present a major challenge. Under water, the sources of variability are due to other factors such as water conditions or growth of marine organisms. Yet it remains a major obstacle and a much less studied one, partly due to the lack of data. We have published a new deep-sea dataset to benchmark underwater long-term visual localization. The dataset is composed of images from four visits to the same hydrothermal vent edifice over the course of five years. Camera poses and a common geometry of the scene were estimated using navigation data and Structure-from-Motion. This serves as a reference when evaluating visual localization techniques. An analysis of the data provides insights about the major changes observed throughout the years. Furthermore, several well-established visual localization methods are evaluated on the dataset, showing there is still room for improvement in underwater long-term visual localization. The data is made publicly available at https://www.seanoe.org/data/00810/92226/.


 Underwater images are altered by the physical characteristics of the medium through which light rays pass before reaching the optical sensor. Scattering and wavelength-dependent absorption significantly modify the captured colors depending on the distance of observed elements to the image plane. We have worked to recover an image of the scene as if the water had no effect on light propagation. We introduce SUCRe, a novel method that exploits the scene’s 3D structure for underwater color restoration. By following points in multiple images and tracking their intensities at different distances to the sensor, we constrain the optimization of the parameters in an underwater image formation model and retrieve unattenuated pixel intensities. We conduct extensive quantitative and qualitative analyses of our approach in a variety of scenarios ranging from natural light to deep-sea environments using three underwater datasets acquired from real-world scenarios and one synthetic dataset. We also compare the performance of the proposed approach with that of a wide range of existing state-of-the-art methods. The results demonstrate a consistent benefit of exploiting multiple views across a spectrum of objective metrics.
Underwater images are altered by the physical characteristics of the medium through which light rays pass before reaching the optical sensor. Scattering and wavelength-dependent absorption significantly modify the captured colors depending on the distance of observed elements to the image plane. We have worked to recover an image of the scene as if the water had no effect on light propagation. We introduce SUCRe, a novel method that exploits the scene’s 3D structure for underwater color restoration. By following points in multiple images and tracking their intensities at different distances to the sensor, we constrain the optimization of the parameters in an underwater image formation model and retrieve unattenuated pixel intensities. We conduct extensive quantitative and qualitative analyses of our approach in a variety of scenarios ranging from natural light to deep-sea environments using three underwater datasets acquired from real-world scenarios and one synthetic dataset. We also compare the performance of the proposed approach with that of a wide range of existing state-of-the-art methods. The results demonstrate a consistent benefit of exploiting multiple views across a spectrum of objective metrics.