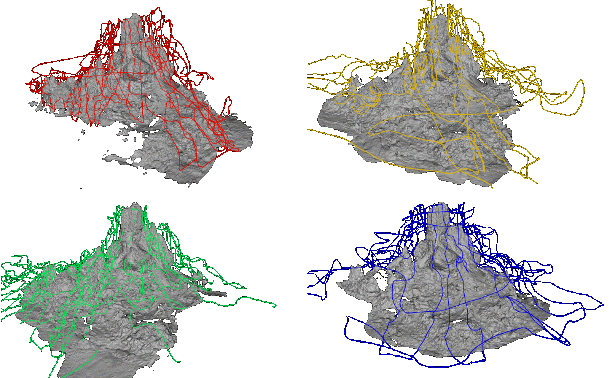
Eiffel Tower: A deep-sea underwater dataset for long-term visual localization
Images from four visits to the same hydrothermal vent edifice over the course of five years. Camera poses and a common geometry of the scene were estimated using navigation data and Structure-from-Motion. This serves as a reference when evaluating visual localization techniques. An analysis of the data provides insights about the major changes observed throughout the years.
Clémentin Boittiaux, Claire Dune, Maxime Ferrera, Aurélien Arnaubec, Ricard Marxer, Marjolaine Matabos, Loic Van Audenhaege, Vincent Hugel
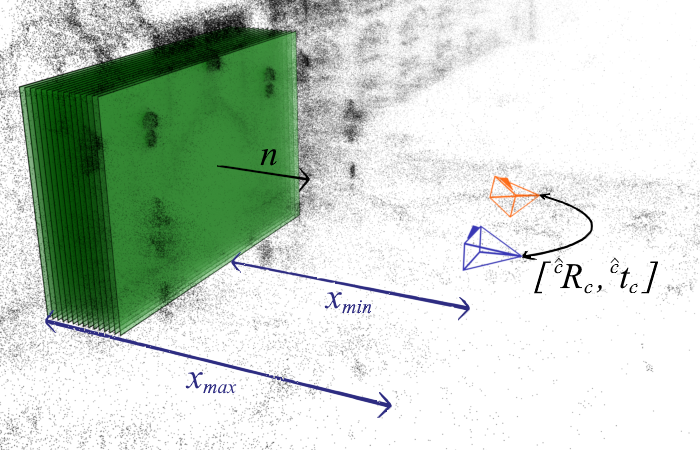
Homography-Based Loss Function for Camera Pose Regression
A novel loss function which is based on a multiplane homography integration. This new function does not require prior initialization and only depends on physically interpretable hyperparameters. It minimizes best the mean square reprojection error during training when compared with existing loss functions.
Clémentin Boittiaux, Ricard Marxer, Claire Dune, Aurélien Arnaubec, Vincent Hugel
The impact of the Lombard effect on audio and visual speech recognition systems
Analysis of audio and visual Lombard speech using new 54 speaker database. New data on the inter-speaker variability of the Lombard effect. Measurement of the impact of Lombard mismatch in a noise robust speech recognition system. Detailed analysis of plain speech versus Lombard speech performance in well-adapted recognition system. Evidence that visual Lombard speech supports higher recognition performance than visual plain speech.
Ricard Marxer, Jon Barker, Najwa Alghamdi, Steve Maddock
Cuervo, S., & Marxer, R. (2023). On the Benefits of Self-supervised Learned Speech Representations for Predicting Human Phonetic Misperceptions. In INTERSPEECH 2023 (pp. 1788–1792). Dublin, Ireland: ISCA. https://doi.org/10.21437/Interspeech.2023-1476
@inproceedings{cuervo:hal-04194225,
title = {{On the Benefits of Self-supervised Learned Speech Representations for Predicting Human Phonetic Misperceptions}},
author = {Cuervo, Santiago and Marxer, Ricard},
url = {https://hal.science/hal-04194225},
booktitle = {{INTERSPEECH 2023}},
address = {Dublin, Ireland},
publisher = {{ISCA}},
pages = {1788-1792},
year = {2023},
month = aug,
doi = {10.21437/Interspeech.2023-1476},
keywords = {speech perception intelligibility prediction sublexical intelligibility self-supervised learning speech-in-noise ; speech perception ; intelligibility prediction ; sublexical intelligibility ; self-supervised learning ; speech-in-noise},
pdf = {https://hal.science/hal-04194225/file/cuervo23_interspeech.pdf},
hal_id = {hal-04194225},
hal_version = {v1}
}
Moore, R. K., & Marxer, R. (2023). Progress and Prospects for Spoken Language Technology: Results from Five Sexennial Surveys. In INTERSPEECH 2023 (pp. 401–405). Dublin, Ireland: ISCA. https://doi.org/10.21437/Interspeech.2023-235
@inproceedings{moore:hal-04194224,
title = {{Progress and Prospects for Spoken Language Technology: Results from Five Sexennial Surveys}},
author = {Moore, Roger K and Marxer, Ricard},
url = {https://hal.science/hal-04194224},
booktitle = {{INTERSPEECH 2023}},
address = {Dublin, Ireland},
publisher = {{ISCA}},
pages = {401-405},
year = {2023},
month = aug,
doi = {10.21437/Interspeech.2023-235},
keywords = {speech recognition speech synthesis survey of progress future predictions ; speech recognition ; speech synthesis ; survey of progress ; future predictions},
pdf = {https://hal.science/hal-04194224/file/moore23_interspeech.pdf},
hal_id = {hal-04194224},
hal_version = {v1}
}
Richards, F., Paiement, A., Xie, X., Sola, E., & Duc, P.-A. (2023). Panoptic Segmentation of Galactic Structures in LSB Images. In 18th International Conference on Machine Vision Applications. Hamamatsu, Shizuoka, Japan. Retrieved from https://hal.science/hal-04129549
@inproceedings{richards:hal-04129549,
title = {{Panoptic Segmentation of Galactic Structures in LSB Images}},
author = {Richards, Felix and Paiement, Adeline and Xie, Xianghua and Sola, Elisabeth and Duc, Pierre-Alain},
url = {https://hal.science/hal-04129549},
booktitle = {{18th International Conference on Machine Vision Applications}},
address = {Hamamatsu, Shizuoka, Japan},
year = {2023},
month = jul,
pdf = {https://hal.science/hal-04129549/file/Multi_class_Segmentation_of_Galactic_Structures.pdf},
hal_id = {hal-04129549},
hal_version = {v1}
}
Best, P., Paris, S., Glotin, H., & Marxer, R. (2023). Deep audio embeddings for vocalisation clustering. PLoS ONE, 18(7), e0283396. https://doi.org/10.1371/journal.pone.0283396
@article{best:hal-04194226,
title = {{Deep audio embeddings for vocalisation clustering}},
author = {Best, Paul and Paris, S{\'e}bastien and Glotin, Herv{\'e} and Marxer, Ricard},
url = {https://hal.science/hal-04194226},
journal = {{PLoS ONE}},
publisher = {{Public Library of Science}},
volume = {18},
number = {7},
pages = {e0283396},
year = {2023},
month = jul,
doi = {10.1371/journal.pone.0283396},
pdf = {https://hal.science/hal-04194226/file/journal.pone.0283396.pdf},
hal_id = {hal-04194226},
hal_version = {v1}
}
Sanz, P., Marín, R., López-Barajas, S., Solis, A., Marxer, R., & Hugel, V. (2023). 1st Year of running MIR at UJI. In OCEANS 2023 - Limerick (pp. 1–5). Limerick, Ireland: IEEE. https://doi.org/10.1109/OCEANSLimerick52467.2023.10244270
@inproceedings{sanz:hal-04208111,
title = {{1st Year of running MIR at UJI}},
author = {Sanz, Pedro and Mar{\'i}n, Ra{\'u}l and L{\'o}pez-Barajas, Salvador and Solis, Alejandro and Marxer, Ricard and Hugel, Vincent},
url = {https://hal.science/hal-04208111},
booktitle = {{OCEANS 2023 - Limerick}},
address = {Limerick, Ireland},
publisher = {{IEEE}},
pages = {1-5},
year = {2023},
month = jun,
doi = {10.1109/OCEANSLimerick52467.2023.10244270},
hal_id = {hal-04208111},
hal_version = {v1}
}
Boittiaux, C., Dune, C., Arnaubec, A., Marxer, R., Ferrera, M., & Hugel, V. (2023). Long-term visual localization in deep-sea underwater environment. In ORASIS. Carqueiranne, France: Thanh Phuong Nguyen. Retrieved from https://hal.science/hal-04108737
@inproceedings{boittiaux:hal-04108737,
title = {{Long-term visual localization in deep-sea underwater environment}},
author = {Boittiaux, Cl{\'e}mentin and Dune, Claire and Arnaubec, Aur{\'e}lien and Marxer, Ricard and Ferrera, Maxime and Hugel, Vincent},
url = {https://hal.science/hal-04108737},
booktitle = {{ORASIS}},
address = {Carqueiranne, France},
organization = {{Thanh Phuong Nguyen}},
year = {2023},
month = may,
keywords = {Visual localization ; Marine robotics ; Localisation visuelle ; Robotique sous-marine},
pdf = {https://hal.science/hal-04108737/file/Underwater_Benchmark___ORASIS_2023___Boittiaux.pdf},
hal_id = {hal-04108737},
hal_version = {v1}
}
Gibbs, L., Bingham, R. J., & Paiement, A. (2023). A novel filtering method for geodetically-determined ocean surface currents using deep learning. Environmental Data Science. Retrieved from https://hal.science/hal-04285643
@article{gibbs:hal-04285643,
title = {{A novel filtering method for geodetically-determined ocean surface currents using deep learning}},
author = {Gibbs, Laura and Bingham, Rory J and Paiement, Adeline},
url = {https://hal.science/hal-04285643},
journal = {{Environmental Data Science}},
publisher = {{Cambridge University Press}},
year = {2023},
keywords = {mean dynamic topography ; geostrophic currents ; deep learning ; filtering ; generative networks},
pdf = {https://hal.science/hal-04285643/file/Environmental_data_science_final_preprint.pdf},
hal_id = {hal-04285643},
hal_version = {v1}
}
Patris, J., Malige, F., Hamame, M., Glotin, H., Barchasz, V., Gies, V., … Buchan, S. (2023). Medium-term acoustic monitoring of small cetaceans in Patagonia, Chile. PeerJ, 11, e15292. https://doi.org/10.7717/peerj.15292
@article{patris:hal-04128643,
title = {{Medium-term acoustic monitoring of small cetaceans in Patagonia, Chile}},
author = {Patris, Julie and Malige, Franck and Hamame, Madeleine and Glotin, Herv{\'e} and Barchasz, Valentin and Gies, Valentin and Marzetti, Sebastian and Buchan, Susannah},
url = {https://hal.science/hal-04128643},
journal = {{PeerJ}},
publisher = {{PeerJ}},
volume = {11},
pages = {e15292},
year = {2023},
doi = {10.7717/peerj.15292},
keywords = {Bioacoustics ; Remote sensing ; Patagonian ecosystem ; Coastal small cetaceans ; Chilean dolphin ; C-POD},
pdf = {https://hal.science/hal-04128643/file/2023_Patris_Medium-term_acoustic_monitoring_of_small_cetaceans_in_Patagonia_Chile.pdf},
hal_id = {hal-04128643},
hal_version = {v1}
}
Boittiaux, C., Dune, C., Ferrera, M., Arnaubec, A., Marxer, R., Matabos, M., … Hugel, V. (2023). Eiffel Tower: A Deep-Sea Underwater Dataset for Long-Term Visual Localization. The International Journal of Robotics Research. https://doi.org/10.1177/02783649231177322
@article{boittiaux:hal-04089339,
title = {{Eiffel Tower: A Deep-Sea Underwater Dataset for Long-Term Visual Localization}},
author = {Boittiaux, Cl{\'e}mentin and Dune, Claire and Ferrera, Maxime and Arnaubec, Aur{\'e}lien and Marxer, Ricard and Matabos, Marjolaine and Van Audenhaege, Lo{\"i}c and Hugel, Vincent},
url = {https://hal.science/hal-04089339},
journal = {{The International Journal of Robotics Research}},
publisher = {{SAGE Publications}},
year = {2023},
doi = {10.1177/02783649231177322},
keywords = {Underwater dataset ; Visual localization ; Deep-sea imagery},
pdf = {https://hal.science/hal-04089339/file/EiffelTower.pdf},
hal_id = {hal-04089339},
hal_version = {v1}
}
Sarano, F., Sarano, V., Tonietto, M.-L., Yernaux, A., Jung, J.-L., Arribart, M., … Adam, O. (2023). Nursing Behavior in Sperm Whales (Physeter macrocephalus). Animal Behavior and Cognition, 10(2), 105–131. https://doi.org/10.26451/abc.10.02.02.2023
@article{sarano:hal-04207557,
title = {{Nursing Behavior in Sperm Whales (Physeter macrocephalus)}},
author = {Sarano, Fran{\c c}ois and Sarano, V{\'e}ronique and Tonietto, Modan-Lou and Yernaux, Adrien and Jung, Jean-Luc and Arribart, Marion and Girardet, Justine and Preud'Homme, Axel and Heuzey, Ren{\'e} and Delfour, Fabienne and Glotin, Herv{\'e} and Charrier, Isabelle and Adam, Olivier},
url = {https://hal.science/hal-04207557},
journal = {{Animal Behavior and Cognition}},
publisher = {{Animal Behavior and Cognition}},
volume = {10},
number = {2},
pages = {105-131},
year = {2023},
doi = {10.26451/abc.10.02.02.2023},
keywords = {Sperm whale ; Nursing ; Allonursing ; Suckling ; Underwater observations},
pdf = {https://hal.science/hal-04207557/file/Nursing-Behavior-Sperm-Whales-Sarano_et_al_ABC_10%282%29.pdf},
hal_id = {hal-04207557},
hal_version = {v1}
}
Cuervo, S., Łańcucki, A., Marxer, R., Rychlikowski, P., & Chorowski, J. (2022). Variable-rate hierarchical CPC leads to acoustic unit discovery in speech. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, & A. Oh (Eds.), Advances in Neural Information Processing Systems 35 (NeurIPS 2022) (Vol. 35, pp. 34995–35006). New Orleans, United States: Curran Associates, Inc. Retrieved from https://hal.science/hal-04093636
@inproceedings{cuervo:hal-04093636,
title = {{Variable-rate hierarchical CPC leads to acoustic unit discovery in speech}},
author = {Cuervo, Santiago and Ła{\'n}cucki, Adrian and Marxer, Ricard and Rychlikowski, Pawel and Chorowski, Jan},
url = {https://hal.science/hal-04093636},
note = {Accepted to 36th Conference on Neural Information Processing Systems (NeurIPS 2022)},
booktitle = {{Advances in Neural Information Processing Systems 35 (NeurIPS 2022)}},
address = {New Orleans, United States},
editor = {Koyejo, S. and Mohamed, S. and Agarwal, A. and Belgrave, D. and Cho, K. and Oh, A.},
publisher = {{Curran Associates, Inc.}},
volume = {35},
pages = {34995-35006},
year = {2022},
month = nov,
keywords = {Sound ; Computation and Language ; Machine Learning ; Neural and Evolutionary Computing ; Audio and Speech Processing},
pdf = {https://hal.science/hal-04093636/file/NeurIPS-2022-variable-rate-hierarchical-cpc-leads-to-acoustic-unit-discovery-in-speech-Paper-Conference.pdf},
hal_id = {hal-04093636},
hal_version = {v1}
}
Dinar, F., Chayla, R., Paris, S., & Busvelle, E. (2022). A low-level set of stationary features dedicated to non-intrusive load monitoring. In International Conference on Systems and Control. Marseille, France. Retrieved from https://hal.science/hal-03855164
@inproceedings{dinar:hal-03855164,
title = {{A low-level set of stationary features dedicated to non-intrusive load monitoring}},
author = {Dinar, Farid and Chayla, Romain and Paris, S{\'e}bastien and Busvelle, Eric},
url = {https://hal.science/hal-03855164},
booktitle = {{International Conference on Systems and Control}},
address = {Marseille, France},
year = {2022},
month = nov,
pdf = {https://hal.science/hal-03855164/file/ICSC_22.pdf},
hal_id = {hal-03855164},
hal_version = {v1}
}
Richards, F., Xie, X., Paiement, A., Sola, E., & Duc, P.-A. (2022). MULTI-SCALE GRIDDED GABOR ATTENTION FOR CIRRUS SEGMENTATION. In IEEE International Conference on Image Processing (ICIP). Bordeaux, France. https://doi.org/10.1109/ICIP46576.2022.9898045
@inproceedings{richards:hal-04062643,
title = {{MULTI-SCALE GRIDDED GABOR ATTENTION FOR CIRRUS SEGMENTATION}},
author = {Richards, Felix and Xie, Xianghua and Paiement, Adeline and Sola, Elisabeth and Duc, Pierre-Alain},
url = {https://hal.science/hal-04062643},
booktitle = {{IEEE International Conference on Image Processing (ICIP)}},
address = {Bordeaux, France},
year = {2022},
month = oct,
doi = {10.1109/ICIP46576.2022.9898045},
keywords = {Attention ; multi-scale ; orientation ; segmentation ; astronomy},
pdf = {https://hal.science/hal-04062643/file/ICIP_cirrus_camera_ready.pdf},
hal_id = {hal-04062643},
hal_version = {v1}
}
Lehnhoff, L., Glotin, H., Bernard, S., Dabin, W., Le Gall, Y., Menut, E., … Mérigot, B. (2022). Behavioural Responses of Common Dolphins Delphinus delphis to a Bio-Inspired Acoustic Device for Limiting Fishery By-Catch. Sustainability, 14(20), 13186. https://doi.org/10.3390/su142013186
@article{lehnhoff:hal-03820889,
title = {{Behavioural Responses of Common Dolphins Delphinus delphis to a Bio-Inspired Acoustic Device for Limiting Fishery By-Catch}},
author = {Lehnhoff, Lo{\"i}c and Glotin, Herv{\'e} and Bernard, Serge and Dabin, Willy and Le Gall, Yves and Menut, Eric and Meheust, Eleonore and Peltier, H{\'e}l{\`e}ne and Pochat, Alain and Pochat, Krystel and Rimaud, Thomas and Sourget, Quiterie and Spitz, J{\'e}r{\^o}me and Van Canneyt, Olivier and M{\'e}rigot, Bastien},
url = {https://hal.umontpellier.fr/hal-03820889},
journal = {{Sustainability}},
publisher = {{MDPI}},
volume = {14},
number = {20},
pages = {13186},
year = {2022},
month = oct,
doi = {10.3390/su142013186},
keywords = {bio-acoustics ; etho-acoustic ; cetaceans ; echolocation ; clicks ; whistles ; buzz ; burst-pulse ; sound processing ; Bay of Biscay},
pdf = {https://hal.umontpellier.fr/hal-03820889/file/sustainability-14-13186.pdf},
hal_id = {hal-03820889},
hal_version = {v1}
}
Hafsati, M., Bentounes, K., & Marxer, R. (2022). Blind Speech Separation Through Direction of Arrival Estimation Using Deep Neural Networks with a Flexibility on the Number of Speakers. In 2022 IEEE 24th International Workshop on Multimedia Signal Processing (MMSP) (pp. 1–5). Shanghai, China: IEEE. https://doi.org/10.1109/MMSP55362.2022.9949050
@inproceedings{hafsati:hal-03948355,
title = {{Blind Speech Separation Through Direction of Arrival Estimation Using Deep Neural Networks with a Flexibility on the Number of Speakers}},
author = {Hafsati, Mohammed and Bentounes, Kamil and Marxer, Ricard},
url = {https://hal.science/hal-03948355},
booktitle = {{2022 IEEE 24th International Workshop on Multimedia Signal Processing (MMSP)}},
address = {Shanghai, China},
publisher = {{IEEE}},
pages = {1-5},
year = {2022},
month = sep,
doi = {10.1109/MMSP55362.2022.9949050},
hal_id = {hal-03948355},
hal_version = {v1}
}
Boittiaux, C., Marxer, R., Dune, C., Arnaubec, A., & Hugel, V. (2022). Homography-Based Loss Function for Camera Pose Regression. IEEE Robotics and Automation Letters, 7(3), 6242–6249. https://doi.org/10.1109/LRA.2022.3168329
@article{boittiaux:hal-03654445,
title = {{Homography-Based Loss Function for Camera Pose Regression}},
author = {Boittiaux, Cl{\'e}mentin and Marxer, Ricard and Dune, Claire and Arnaubec, Aur{\'e}lien and Hugel, Vincent},
url = {https://hal.science/hal-03654445},
journal = {{IEEE Robotics and Automation Letters}},
publisher = {{IEEE }},
volume = {7},
number = {3},
pages = {6242-6249},
year = {2022},
month = jul,
doi = {10.1109/LRA.2022.3168329},
keywords = {Localization ; Deep Learning for Visual Perception},
pdf = {https://hal.science/hal-03654445/file/RA_L_2022_clean.pdf},
hal_id = {hal-03654445},
hal_version = {v1}
}
Rojas-cerda, C., Buchan, S. J., Branch, T. A., Malige, F., Patris, J., Hucke-gaete, R., & Staniland, I. (2022). Presence of Southeast Pacific blue whales ( Balaenoptera musculus ) off South Georgia in the South Atlantic Ocean. Marine Mammal Science, 38, 1425–1441. https://doi.org/10.1111/mms.12946
@article{rojascerda:hal-03812724,
title = {{Presence of Southeast Pacific blue whales ( Balaenoptera musculus ) off South Georgia in the South Atlantic Ocean}},
author = {Rojas-cerda, Constanza and Buchan, Susannah J and Branch, Trevor A and Malige, Franck and Patris, Julie and Hucke-gaete, Rodrigo and Staniland, Iain},
url = {https://cnrs.hal.science/hal-03812724},
journal = {{Marine Mammal Science}},
publisher = {{Wiley}},
volume = {38},
pages = {1425 - 1441},
year = {2022},
month = jun,
doi = {10.1111/mms.12946},
hal_id = {hal-03812724},
hal_version = {v1}
}
Malige, F., Patris, J., Hauray, M., Giraudet, P., Glotin, H., & Noûs, C. (2022). Mathematical models of long term evolution of blue whale song types’ frequencies. Journal of Theoretical Biology, 548, 111184. https://doi.org/10.1016/j.jtbi.2022.111184
@article{malige:hal-03632687,
title = {{Mathematical models of long term evolution of blue whale song types' frequencies}},
author = {Malige, Franck and Patris, Julie and Hauray, Maxime and Giraudet, Pascale and Glotin, Herv{\'e} and No{\^u}s, Camille},
url = {https://hal.science/hal-03632687},
journal = {{Journal of Theoretical Biology}},
publisher = {{Elsevier}},
volume = {548},
pages = {111184},
year = {2022},
month = jun,
doi = {10.1016/j.jtbi.2022.111184},
keywords = {blue whale ; song ; flocking ; agent-based model ; consensus seeking},
pdf = {https://hal.science/hal-03632687v2/file/2022_Malige_et_al_Mathematical_models_of_long_term_evolution_of_blue_whale_song_types_frequencies.pdf},
hal_id = {hal-03632687},
hal_version = {v2}
}
Cuervo, S., Grabias, M., Chorowski, J., Ciesielski, G., Lancucki, A., Rychlikowski, P., & Marxer, R. (2022). Contrastive Prediction Strategies for Unsupervised Segmentation and Categorization of Phonemes and Words. In ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 3189–3193). Singapore, France: IEEE. https://doi.org/10.1109/ICASSP43922.2022.9746102
@inproceedings{cuervo:hal-03824772,
title = {{Contrastive Prediction Strategies for Unsupervised Segmentation and Categorization of Phonemes and Words}},
author = {Cuervo, Santiago and Grabias, Maciej and Chorowski, Jan and Ciesielski, Grzegorz and Lancucki, Adrian and Rychlikowski, Pawel and Marxer, Ricard},
url = {https://hal.science/hal-03824772},
booktitle = {{ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}},
address = {Singapore, France},
publisher = {{IEEE}},
pages = {3189-3193},
year = {2022},
month = may,
doi = {10.1109/ICASSP43922.2022.9746102},
pdf = {https://hal.science/hal-03824772/file/2110.15909.pdf},
hal_id = {hal-03824772},
hal_version = {v1}
}
Poupard, M., Ferrari, M., Best, P., & Glotin, H. (2022). Passive acoustic monitoring of sperm whales and anthropogenic noise using stereophonic recordings in the Mediterranean Sea, North West Pelagos Sanctuary. Scientific Reports. Retrieved from https://hal.science/hal-03561786
@article{poupard:hal-03561786,
title = {{Passive acoustic monitoring of sperm whales and anthropogenic noise using stereophonic recordings in the Mediterranean Sea, North West Pelagos Sanctuary}},
author = {Poupard, Marion and Ferrari, Maxence and Best, Paul and Glotin, Herv{\'e}},
url = {https://hal.science/hal-03561786},
journal = {{Scientific Reports}},
publisher = {{Nature Publishing Group}},
year = {2022},
month = feb,
hal_id = {hal-03561786},
hal_version = {v1}
}
Almahasneh, M., Paiement, A., Xie, X., & Aboudarham, J. (2022). MSMT-CNN for solar active region detection with multi-spectral analysis. SN Computer Science. https://doi.org/10.1007/s42979-022-01088-y
@article{almahasneh:hal-03584929,
title = {{MSMT-CNN for solar active region detection with multi-spectral analysis}},
author = {Almahasneh, Majedaldein and Paiement, Adeline and Xie, Xianghua and Aboudarham, Jean},
url = {https://hal.science/hal-03584929},
journal = {{SN Computer Science}},
publisher = {{Springer}},
year = {2022},
doi = {10.1007/s42979-022-01088-y},
keywords = {Object detection ; Solar images ; Active regions ; Multi-spectral images ; Deep neural networks},
pdf = {https://hal.science/hal-03584929/file/Revised_Springer_Nature_SN_CS.pdf},
hal_id = {hal-03584929},
hal_version = {v1}
}
Sola, E., Duc, P.-A., Richards, F., Paiement, A., Urbano, M., Klehammer, J., … Mcconnachie, A. (2022). Characterization of low surface brightness structures in annotated deep images. Astronomy and Astrophysics - A&A, 662, A124. https://doi.org/10.1051/0004-6361/202142675
@article{sola:hal-03711971,
title = {{Characterization of low surface brightness structures in annotated deep images}},
author = {Sola, Elisabeth and Duc, Pierre-Alain and Richards, Felix and Paiement, Adeline and Urbano, Mathias and Klehammer, Julie and B{\'i}lek, Michal and Cuillandre, Jean-Charles and Gwyn, Stephen and Mcconnachie, Alan},
url = {https://hal.science/hal-03711971},
journal = {{Astronomy and Astrophysics - A\&A}},
publisher = {{EDP Sciences}},
volume = {662},
pages = {A124},
year = {2022},
doi = {10.1051/0004-6361/202142675},
keywords = {galaxies: interactions ; galaxies: evolution ; methods: data analysis},
pdf = {https://hal.science/hal-03711971/file/aa42675-21.pdf},
hal_id = {hal-03711971},
hal_version = {v1}
}
Best, P., Marxer, R., Paris, S., & Glotin, H. (2022). Temporal evolution of the Mediterranean fin whale song. Scientific Reports, 12(1), 13565. https://doi.org/10.1038/s41598-022-15379-0
@article{best:hal-03824738,
title = {{Temporal evolution of the Mediterranean fin whale song}},
author = {Best, Paul and Marxer, Ricard and Paris, S{\'e}bastien and Glotin, Herv{\'e}},
url = {https://hal.science/hal-03824738},
journal = {{Scientific Reports}},
publisher = {{Nature Publishing Group}},
volume = {12},
number = {1},
pages = {13565},
year = {2022},
doi = {10.1038/s41598-022-15379-0},
pdf = {https://hal.science/hal-03824738/file/s41598-022-15379-0.pdf},
hal_id = {hal-03824738},
hal_version = {v1}
}
Chetouani, M., Mandel-Briefer, E., Dassow, A., Marxer, R., Moore, R., Obin, N., & Stowell, D. (2021). Proceedings of the 3rd International Workshop on Vocal Interactivity in-and-between Humans, Animals and Robots (VIHAR 2021). Retrieved from https://hal.science/hal-03429487
@book{chetouani:hal-03429487,
title = {{Proceedings of the 3rd International Workshop on Vocal Interactivity in-and-between Humans, Animals and Robots (VIHAR 2021)}},
author = {Chetouani, Mohamed and Mandel-Briefer, Elodie and Dassow, Angela and Marxer, Ricard and Moore, Roger and Obin, Nicolas and Stowell, Dan},
url = {https://hal.science/hal-03429487},
year = {2021},
month = oct,
hal_id = {hal-03429487},
hal_version = {v1}
}
Poupard, M., Symonds, H., Spong, P., & Glotin, H. (2021). Intra-Group Orca Call Rate Modulation Estimation Using Compact Four Hydrophones Array. Frontiers in Marine Science. Retrieved from https://hal.science/hal-03555012
@article{poupard:hal-03555012,
title = {{Intra-Group Orca Call Rate Modulation Estimation Using Compact Four Hydrophones Array}},
author = {Poupard, Marion and Symonds, Helena and Spong, Paul and Glotin, Herv{\'e}},
url = {https://hal.science/hal-03555012},
journal = {{Frontiers in Marine Science}},
publisher = {{Frontiers Media}},
year = {2021},
month = oct,
hal_id = {hal-03555012},
hal_version = {v1}
}
Joly, A., Goëau, H., Kahl, S., Picek, L., Lorieul, T., Cole, E., … Müller, H. (2021). Overview of LifeCLEF 2021: an evaluation of Machine-Learning based Species Identification and Species Distribution Prediction. In K. S. Candan, B. Ionescu, L. Goeuriot, B. Larsen, H. Müller, A. Joly, … N. Ferro (Eds.), CLEF 2021 - 12th International Conference of the CLEF Association (Vol. LNCS. LNISA - 12880, pp. 371–393). Virtual Event, France: Springer International Publishing. https://doi.org/10.1007/978-3-030-85251-1_24
@inproceedings{joly:hal-03415990,
title = {{Overview of LifeCLEF 2021: an evaluation of Machine-Learning based Species Identification and Species Distribution Prediction}},
author = {Joly, Alexis and Go{\"e}au, Herv{\'e} and Kahl, Stefan and Picek, Luk{\'a}{\v s} and Lorieul, Titouan and Cole, Elijah and Deneu, Benjamin and Servajean, Maximilien and Durso, Andrew and Bolon, Isabelle and Glotin, Herv{\'e} and Planqu{\'e}, Robert and de Casta{\~n}eda, Rafael Ruiz and Vellinga, Willem-Pier and Klinck, Holger and Denton, Tom and Eggel, Ivan and Bonnet, Pierre and M{\"u}ller, Henning},
url = {https://inria.hal.science/hal-03415990},
booktitle = {{CLEF 2021 - 12th International Conference of the CLEF Association}},
address = {Virtual Event, France},
hal_local_reference = {BIAS},
editor = {Candan, K. Sel{\c c}uk and Ionescu, Bogdan and Goeuriot, Lorraine and Larsen, Birger and M{\"u}ller, Henning and Joly, Alexis and Maistro, Maria and Piroi, Florina and Faggioli, Guglielmo and Ferro, Nicola},
publisher = {{Springer International Publishing}},
series = {Experimental IR Meets Multilinguality, Multimodality, and Interaction},
volume = {LNCS. LNISA - 12880},
pages = {371-393},
year = {2021},
month = sep,
doi = {10.1007/978-3-030-85251-1\_24},
keywords = {Species Identification ; Species Distribution Prediction},
pdf = {https://inria.hal.science/hal-03415990/file/Lifeclef2021.pdf},
hal_id = {hal-03415990},
hal_version = {v1}
}
Marxer, R., Hugel, V., Prud’Homme, K. P., Batista, P., Aviles, J. V. M., Pascoal, A., … Schjolberg, I. (2021). Marine and Maritime Intelligent Robotics (MIR). In OCEANS 2021: San Diego – Porto. San Diego, France: IEEE. https://doi.org/10.23919/OCEANS44145.2021.9706122
@inproceedings{marxer:hal-03583552,
title = {{Marine and Maritime Intelligent Robotics (MIR)}},
author = {Marxer, Ricard and Hugel, Vincent and Prud'Homme, Kalliopi Pediaditi and Batista, Pedro and Aviles, Jose Vicente Marti and Pascoal, Antonio and Sanz, Pedro and Schjolberg, Ingrid},
url = {https://hal.science/hal-03583552},
booktitle = {{OCEANS 2021: San Diego -- Porto}},
address = {San Diego, France},
publisher = {{IEEE}},
year = {2021},
month = sep,
doi = {10.23919/OCEANS44145.2021.9706122},
pdf = {https://hal.science/hal-03583552/file/Marine_and_maritime_Intelligent_Robotics__MIR_%20%285%29.pdf},
hal_id = {hal-03583552},
hal_version = {v1}
}
Chorowski, J., Ciesielski, G., Dzikowski, J., Łańcucki, A., Marxer, R., Opala, M., … Stypulkowski, M. (2021). Information Retrieval for ZeroSpeech 2021: The Submission by University of Wroclaw. In Interspeech 2021 (pp. 971–975). Brno, Czech Republic: ISCA. https://doi.org/10.21437/Interspeech.2021-1465
@inproceedings{chorowski:hal-03408592,
title = {{Information Retrieval for ZeroSpeech 2021: The Submission by University of Wroclaw}},
author = {Chorowski, Jan and Ciesielski, Grzegorz and Dzikowski, Jaroslaw and Ła{\'n}cucki, Adrian and Marxer, Ricard and Opala, Mateusz and Pusz, Piotr and Rychlikowski, Pawel and Stypulkowski, Michal},
url = {https://hal.science/hal-03408592},
booktitle = {{Interspeech 2021}},
address = {Brno, Czech Republic},
publisher = {{ISCA}},
pages = {971-975},
year = {2021},
month = aug,
doi = {10.21437/Interspeech.2021-1465},
pdf = {https://hal.science/hal-03408592/file/chorowski21_interspeech.pdf},
hal_id = {hal-03408592},
hal_version = {v1}
}
Chorowski, J., Ciesielski, G., Dzikowski, J., Łańcucki, A., Marxer, R., Opala, M., … Stypulkowski, M. (2021). Aligned Contrastive Predictive Coding. In Interspeech 2021 (pp. 976–980). Brno, Czech Republic: ISCA. https://doi.org/10.21437/interspeech.2021-1544
@inproceedings{chorowski:hal-03408618,
title = {{Aligned Contrastive Predictive Coding}},
author = {Chorowski, Jan and Ciesielski, Grzegorz and Dzikowski, Jaroslaw and Ła{\'n}cucki, Adrian and Marxer, Ricard and Opala, Mateusz and Pusz, Piotr and Rychlikowski, Pawel and Stypulkowski, Michal},
url = {https://hal.science/hal-03408618},
booktitle = {{Interspeech 2021}},
address = {Brno, Czech Republic},
publisher = {{ISCA}},
pages = {976-980},
year = {2021},
month = aug,
doi = {10.21437/interspeech.2021-1544},
keywords = {self-supervised learning ; contrast predictive coding ; dynamic time warping ; zerospeech},
pdf = {https://hal.science/hal-03408618/file/chorowski21b_interspeech.pdf},
hal_id = {hal-03408618},
hal_version = {v1}
}
Hernaez, I., González-López, J. A., Navas, E., Pérez Córdoba, J. L., Saratxaga, I., Olivares, G., … Diener, L. (2021). Voice Restoration with Silent Speech Interfaces (ReSSInt). In IberSPEECH 2021 (pp. 130–134). Valladolid, Spain: ISCA. https://doi.org/10.21437/IberSPEECH.2021-28
@inproceedings{hernaez:hal-03599182,
title = {{Voice Restoration with Silent Speech Interfaces (ReSSInt)}},
author = {Hernaez, Inma and Gonz{\'a}lez-L{\'o}pez, Jose Andr{\'e}s and Navas, Eva and P{\'e}rez C{\'o}rdoba, Jose Luis and Saratxaga, Ibon and Olivares, Gonzalo and S{\'a}nchez de La Fuente, Jon and Gald{\'o}n, Alberto and Garc{\'i}a Romillo, V{\'i}ctor and Gonz{\'a}lez-Atienza, M{\'i}riam and Schultz, Tanja and Green, Phil and Wand, Michael and Marxer, Ricard and Diener, Lorenz},
url = {https://inria.hal.science/hal-03599182},
booktitle = {{IberSPEECH 2021}},
address = {Valladolid, Spain},
publisher = {{ISCA}},
pages = {130-134},
year = {2021},
month = may,
doi = {10.21437/IberSPEECH.2021-28},
hal_id = {hal-03599182},
hal_version = {v1}
}
Almahasneh, M., Paiement, A., Xie, X., & Aboudarham, J. (2021). Active region detection in multi-spectral solar images. In International Conference on Pattern Recognition Applications and Methods (ICPRAM). online, Austria. Retrieved from https://hal.science/hal-03040990
@inproceedings{almahasneh:hal-03040990,
title = {{Active region detection in multi-spectral solar images}},
author = {Almahasneh, Majedaldein and Paiement, Adeline and Xie, Xianghua and Aboudarham, Jean},
url = {https://hal.science/hal-03040990},
booktitle = {{International Conference on Pattern Recognition Applications and Methods (ICPRAM)}},
address = {online, Austria},
year = {2021},
month = feb,
keywords = {Joint Analysis ; Solar Images ; Active Regions ; Multi-spectral Images},
pdf = {https://hal.science/hal-03040990/file/ICPRAM_2021_75_CR.pdf},
hal_id = {hal-03040990},
hal_version = {v1}
}
Almahasneh, M., Paiement, A., Xie, X., & Aboudarham, J. (2021). MLMT-CNN for Object Detection and Segmentation in Multi-layer and Multi-spectral Images. Machine Vision and Applications, 33, 9. https://doi.org/10.1007/s00138-021-01261-y
@article{almahasneh:hal-03404405,
title = {{MLMT-CNN for Object Detection and Segmentation in Multi-layer and Multi-spectral Images}},
author = {Almahasneh, Majedaldein and Paiement, Adeline and Xie, Xianghua and Aboudarham, Jean},
url = {https://hal.science/hal-03404405},
journal = {{Machine Vision and Applications}},
publisher = {{Springer Verlag}},
volume = {33},
pages = {9},
year = {2021},
doi = {10.1007/s00138-021-01261-y},
keywords = {Image segmentation ; object detection ; deep learning ; weakly supervised learning ; multispectral images ; solar image analysis ; solar active regions},
pdf = {https://hal.science/hal-03404405/file/Machine_Vision_and_Applications___Multi_layer_multi_task_analysis_of_solar_atmosphere_for_active_region_localisation__review__3___SUBMISSION_.pdf},
hal_id = {hal-03404405},
hal_version = {v1}
}
Ferrari, M., Glotin, H., Oger, M., Marxer, R., Asch, M., Gies, V., & Sarano, F. (2020). 3D diarization of a sperm whale click cocktail party by an ultra high sampling rate portable hydrophone array for assessing individual cetacean growth curves. In Forum Acusticum (pp. 3239–3243). Lyon, France. https://doi.org/10.48465/fa.2020.1097
@inproceedings{ferrari:hal-03230843,
title = {{3D diarization of a sperm whale click cocktail party by an ultra high sampling rate portable hydrophone array for assessing individual cetacean growth curves}},
author = {Ferrari, Maxence and Glotin, Herv{\'e} and Oger, Marina and Marxer, Ricard and Asch, Mark and Gies, Valentin and Sarano, Francois},
url = {https://hal.science/hal-03230843},
booktitle = {{Forum Acusticum}},
address = {Lyon, France},
hal_local_reference = {Advances in Big Data Bioacoustics from sensors to deep learning},
pages = {3239-3243},
year = {2020},
month = dec,
doi = {10.48465/fa.2020.1097},
keywords = {3 localisation ; bioacoustics ; near field ; animal diarization},
pdf = {https://hal.science/hal-03230843/file/001097.pdf},
hal_id = {hal-03230843},
hal_version = {v1}
}
Ferrari, M., Glotin, H., & Marxer, R. (2020). End to end raw audio deep learning of transients, application to bioacoustics. In e-Forum Acusticum 2020 (pp. 3245–3247). Lyon, France. https://doi.org/10.48465/fa.2020.1096
@inproceedings{ferrari:hal-03230842,
title = {{End to end raw audio deep learning of transients, application to bioacoustics}},
author = {Ferrari, Maxence and Glotin, Herv{\'e} and Marxer, Ricard},
url = {https://hal.science/hal-03230842},
booktitle = {{e-Forum Acusticum 2020}},
address = {Lyon, France},
hal_local_reference = {Advances in Big Data Bioacoustics from sensors to deep learning},
pages = {3245-3247},
year = {2020},
month = dec,
doi = {10.48465/fa.2020.1096},
keywords = {deep learning ; bioacoustics ; Sperm whale ; transient classification},
pdf = {https://hal.science/hal-03230842/file/001096.pdf},
hal_id = {hal-03230842},
hal_version = {v1}
}
Ferrari, M., Glotin, H., Oger, M., Marxer, R., Asch, M., Gies, V., & Sarano, F. (2020). 3D diarization of a sperm whale click cocktail party by an ultra high sampling rate portable hydrophone array for assessing individual cetacean growth curves. In FA2020. Lyon, France. Retrieved from https://hal.science/hal-03078655
@inproceedings{ferrari:hal-03078655,
title = {{3D diarization of a sperm whale click cocktail party by an ultra high sampling rate portable hydrophone array for assessing individual cetacean growth curves}},
author = {Ferrari, Maxence and Glotin, Herv{\'e} and Oger, Marina and Marxer, Ricard and Asch, Mark and Gies, Valentin and Sarano, Fran{\c c}ois},
url = {https://hal.science/hal-03078655},
booktitle = {{FA2020}},
address = {Lyon, France},
year = {2020},
month = dec,
pdf = {https://hal.science/hal-03078655/file/Click_individual_attribution_by_underwater_multi_hydrophone_acquisition.pdf},
hal_id = {hal-03078655},
hal_version = {v1}
}
Ferrari, M., Glotin, H., & Marxer, R. (2020). END TO END RAW AUDIO DEEP LEARNING OF TRANSIENTS, APPLICATION TO BIOACOUSTICS. In FA2020 (Congrès Français d’Acoustique ). Lyon, France. Retrieved from https://hal.science/hal-03078665
@inproceedings{ferrari:hal-03078665,
title = {{END TO END RAW AUDIO DEEP LEARNING OF TRANSIENTS, APPLICATION TO BIOACOUSTICS}},
author = {Ferrari, Maxence and Glotin, Herv{\'e} and Marxer, Ricard},
url = {https://hal.science/hal-03078665},
booktitle = {{FA2020 (Congr{\`e}s Fran{\c c}ais d'Acoustique )}},
address = {Lyon, France},
year = {2020},
month = dec,
pdf = {https://hal.science/hal-03078665/file/End_to_end_raw_audio_deep_learning_of_clicks.pdf},
hal_id = {hal-03078665},
hal_version = {v1}
}
Best, P., Marzetti, S., Poupard, M., Ferrari, M., Paris, S., Marxer, R., … Glotin, H. (2020). Stereo to five-channels bombyx sonobuoys: from four years cetacean monitoring to real-time whale-ship anti-collision system. In e-Forum Acusticum 2020 (pp. 3229–3231). Lyon, France. https://doi.org/10.48465/fa.2020.1089
@inproceedings{best:hal-03230839,
title = {{Stereo to five-channels bombyx sonobuoys: from four years cetacean monitoring to real-time whale-ship anti-collision system}},
author = {Best, Paul and Marzetti, Sebastian and Poupard, Marion and Ferrari, Maxence and Paris, S{\'e}bastien and Marxer, Ricard and Philippe, Olivier and Gies, Valentin and Barchasz, Valentin and Glotin, Herv{\'e}},
url = {https://hal.science/hal-03230839},
booktitle = {{e-Forum Acusticum 2020}},
address = {Lyon, France},
hal_local_reference = {Advances in Big Data Bioacoustics from sensors to deep learning},
pages = {3229-3231},
year = {2020},
month = dec,
doi = {10.48465/fa.2020.1089},
keywords = {azigram ; stereo sonobuoy ; bioacoutics ; azigram ; cetacean},
pdf = {https://hal.science/hal-03230839/file/001089.pdf},
hal_id = {hal-03230839},
hal_version = {v1}
}
Malige, F., Djokic, D., Patris, J., Sousa-Lima, R., & Glotin, H. (2020). Use of recurrence plots for identification and extraction of patterns in humpback whale song recordings. Bioacoustics, 1–16. https://doi.org/10.1080/09524622.2020.1845240
@article{malige:hal-03008908,
title = {{Use of recurrence plots for identification and extraction of patterns in humpback whale song recordings}},
author = {Malige, Franck and Djokic, Divna and Patris, Julie and Sousa-Lima, Renata and Glotin, Herv{\'e}},
url = {https://hal.science/hal-03008908},
journal = {{Bioacoustics}},
publisher = {{Taylor and Francis}},
pages = {1 - 16},
year = {2020},
month = nov,
doi = {10.1080/09524622.2020.1845240},
keywords = {sound sequences ; soundtranscription ; Humpback whale ; song ; recurrence plot ; song structure ; sound visualization},
pdf = {https://hal.science/hal-03008908/file/Malige_et_al_october_2020_pour_HAL.pdf},
hal_id = {hal-03008908},
hal_version = {v1}
}
Khurana, S., Laurent, A., Hsu, W.-N., Chorowski, J., Łańcucki, A., Marxer, R., & Glass, J. (2020). A Convolutional Deep Markov Model for Unsupervised Speech Representation Learning. In Interspeech 2020. Shanghai, China. Retrieved from https://hal.science/hal-02912029
@inproceedings{khurana:hal-02912029,
title = {{A Convolutional Deep Markov Model for Unsupervised Speech Representation Learning}},
author = {Khurana, Sameer and Laurent, Antoine and Hsu, Wei-Ning and Chorowski, Jan and Ła{\'n}cucki, Adrian and Marxer, Ricard and Glass, James},
url = {https://hal.science/hal-02912029},
booktitle = {{Interspeech 2020}},
address = {Shanghai, China},
year = {2020},
month = oct,
keywords = {Neural Variational Latent Variable Model ; Structured Variational Inference ; Unsupervised Speech Representation Learning},
pdf = {https://hal.science/hal-02912029/file/convDMM_arxiv.pdf},
hal_id = {hal-02912029},
hal_version = {v1}
}
Dolfing, H. J. G. A., Jérome, B., Chorowski, J., Marxer, R., & Laurent, A. (2020). The ”ScribbleLens” Dutch historical handwriting corpus. In International Conference on Frontiers of Handwriting Recognition (ICFHR). Dortmund, Germany. Retrieved from https://hal.science/hal-02877520
@inproceedings{dolfing:hal-02877520,
title = {{The ''ScribbleLens'' Dutch historical handwriting corpus}},
author = {Dolfing, Hans J G A and J{\'e}rome, Bellegarda and Chorowski, Jan and Marxer, Ricard and Laurent, Antoine},
url = {https://hal.science/hal-02877520},
booktitle = {{International Conference on Frontiers of Handwriting Recognition (ICFHR)}},
address = {Dortmund, Germany},
year = {2020},
month = sep,
hal_id = {hal-02877520},
hal_version = {v1}
}
Jenkins, J., Paiement, A., Aboudarham, J., & Bonnin, X. (2020). Physics-informed detection and segmentation of type II solar radio bursts. In British Machine Vision Virtual Conference. Virtual, United Kingdom. Retrieved from https://inria.hal.science/hal-02923001
@inproceedings{jenkins:hal-02923001,
title = {{Physics-informed detection and segmentation of type II solar radio bursts}},
author = {Jenkins, Joseph and Paiement, Adeline and Aboudarham, Jean and Bonnin, Xavier},
url = {https://inria.hal.science/hal-02923001},
booktitle = {{British Machine Vision Virtual Conference}},
address = {Virtual, United Kingdom},
year = {2020},
month = sep,
pdf = {https://inria.hal.science/hal-02923001/file/adaptive_ROI_cameraready.pdf},
hal_id = {hal-02923001},
hal_version = {v1}
}
Ferrari, M., Glotin, H., Marxer, R., & Asch, M. (2020). DOCC10: Open access dataset of marine mammal transient studies and end-to-end CNN classification. In IJCNN. Glasgow, United Kingdom. Retrieved from https://hal.science/hal-02866091
@inproceedings{ferrari:hal-02866091,
title = {{DOCC10: Open access dataset of marine mammal transient studies and end-to-end CNN classification}},
author = {Ferrari, Maxence and Glotin, Herv{\'e} and Marxer, Ricard and Asch, Mark},
url = {https://hal.science/hal-02866091},
booktitle = {{IJCNN}},
address = {Glasgow, United Kingdom},
year = {2020},
month = jul,
keywords = {Index Terms-deep learning ; audio ; bioacoustics ; challenge ; transients ; CNN},
pdf = {https://hal.science/hal-02866091/file/PID6461711.pdf},
hal_id = {hal-02866091},
hal_version = {v1}
}
Łańcucki, A., Chorowski, J., Sanchez, G., Marxer, R., Chen, N., Dolfing, H. J. G. A., … Laurent, A. (2020). Robust Training of Vector Quantized Bottleneck Models. In IJCNN 2020. Glasgow, United Kingdom. Retrieved from https://hal.science/hal-02912027
@inproceedings{acucki:hal-02912027,
title = {{Robust Training of Vector Quantized Bottleneck Models}},
author = {Ła{\'n}cucki, Adrian and Chorowski, Jan and Sanchez, Guillaume and Marxer, Ricard and Chen, Nanxin and Dolfing, Hans J G A and Khurana, Sameer and Alum{\"a}e, Tanel and Laurent, Antoine},
url = {https://hal.science/hal-02912027},
note = {Virtual Conference},
booktitle = {{IJCNN 2020}},
address = {Glasgow, United Kingdom},
year = {2020},
month = jul,
keywords = {VQ-VAE ; k-means ; discrete information bottleneck},
pdf = {https://hal.science/hal-02912027/file/robust_vq_arxiv.pdf},
hal_id = {hal-02912027},
hal_version = {v1}
}
Best, P., Ferrari, M., Poupard, M., Paris, S., Marxer, R., Symonds, H., … Glotin, H. (2020). Deep Learning and Domain Transfer for Orca Vocalization Detection. In International joint conference on neural networks. glasgow, United Kingdom. Retrieved from https://hal.science/hal-02865300
@inproceedings{best:hal-02865300,
title = {{Deep Learning and Domain Transfer for Orca Vocalization Detection}},
author = {Best, Paul and Ferrari, Maxence and Poupard, Marion and Paris, S{\'e}bastien and Marxer, Ricard and Symonds, Helena and Spong, Paul and Glotin, Herv{\'e}},
url = {https://hal.science/hal-02865300},
booktitle = {{International joint conference on neural networks}},
address = {glasgow, United Kingdom},
year = {2020},
month = jul,
keywords = {End-to-end sound recognition ; Orca Vocalizations ; Deep Convolutionnal Neural Networks ; Spectral sound recognition},
pdf = {https://hal.science/hal-02865300/file/IJCNN_ORCALAB.pdf},
hal_id = {hal-02865300},
hal_version = {v1}
}
Sanchez, G., Guis, V., Marxer, R., & Bouchara, F. (2020). Deep learning classification with noisy labels. In ICME Workshop. Londres, United Kingdom. Retrieved from https://hal.science/hal-02552375
@inproceedings{sanchez:hal-02552375,
title = {{Deep learning classification with noisy labels}},
author = {Sanchez, Guillaume and Guis, Vincente and Marxer, Ricard and Bouchara, Frederic},
url = {https://hal.science/hal-02552375},
booktitle = {{ICME Workshop}},
address = {Londres, United Kingdom},
year = {2020},
month = jul,
keywords = {label noise ; noisy training ; noisy dataset ; Index Terms-image classifier},
pdf = {https://hal.science/hal-02552375/file/PID6437789%20%281%29.pdf},
hal_id = {hal-02552375},
hal_version = {v1}
}
Poupard, M., de Montgolfier, B., & Glotin, H. (2020). Ethoacoustic by bayesian non parametric and stochastic neighbor embedding to forecast anthropic pressure on dolphins. In OCEANS. Marseille, France. Retrieved from https://hal.science/hal-02445440
@inproceedings{poupard:hal-02445440,
title = {{Ethoacoustic by bayesian non parametric and stochastic neighbor embedding to forecast anthropic pressure on dolphins}},
author = {Poupard, Marion and de Montgolfier, Benjamin and Glotin, Herv{\'e}},
url = {https://hal.science/hal-02445440},
booktitle = {{OCEANS}},
address = {Marseille, France},
year = {2020},
month = jun,
keywords = {Ethoacoustics ; t-SNE ; Bayesian Non Parametric model ; non linear reduction of dimensionality ; PCA ; whistles ; cetacean ; clustering ; Stenella attenuata},
pdf = {https://hal.science/hal-02445440/file/poupard2019_dolphin.pdf},
hal_id = {hal-02445440},
hal_version = {v1}
}
Patris, J., Buchan, S. J., Stafford, K. M., Findlay, K., Hucke-Gaete, R., Neira, S., … Malige, F. (2020). Inter-annual decrease in pulse rate and peak frequency of Southeast Pacific blue whale song types. Scientific Reports. https://doi.org/10.1038/s41598-020-64613-0
@article{patris:hal-02586669,
title = {{Inter-annual decrease in pulse rate and peak frequency of Southeast Pacific blue whale song types}},
author = {Patris, Julie and Buchan, Susannah J and Stafford, Kathleen M and Findlay, Ken and Hucke-Gaete, Rodrigo and Neira, Sergio and Clark, Christopher and Glotin, Herv{\'e} and Malige, Franck},
url = {https://hal.science/hal-02586669},
journal = {{Scientific Reports}},
publisher = {{Nature Publishing Group}},
year = {2020},
month = may,
doi = {10.1038/s41598-020-64613-0},
keywords = {frequency decrease ; blue whale song},
pdf = {https://hal.science/hal-02586669/file/2020_malige_et_al_inter-annual_decrease_in_pulse_rate_and_peak_frequency_of_Southeast_Pacific_blue_whale_song_types.pdf},
hal_id = {hal-02586669},
hal_version = {v1}
}
Joly, A., Goëau, H., Botella, C., Ruiz de Castaneda, R., Glotin, H., Cole, E., … Müller, H. (2020). LifeCLEF 2020 Teaser: Biodiversity Identification and Prediction Challenges. In ECIR 2020 - 42nd European Conference on IR Research on Advances in Information Retrieval (Vol. Lecture Notes in Computer Science, pp. 542–549). Lisbon, Portugal. https://doi.org/10.1007/978-3-030-45442-5_70
@inproceedings{joly:hal-02873670,
title = {{LifeCLEF 2020 Teaser: Biodiversity Identification and Prediction Challenges}},
author = {Joly, Alexis and Go{\"e}au, Herv{\'e} and Botella, Christophe and Ruiz de Castaneda, Rafael and Glotin, Herv{\'e} and Cole, Elijah and Champ, Julien and Deneu, Benjamin and Servajean, Maximilien and Lorieul, Titouan and Vellinga, Willem-Pier and St{\"o}ter, Fabian-Robert and Durso, Andrew and Bonnet, Pierre and M{\"u}ller, Henning},
url = {https://hal.inrae.fr/hal-02873670},
booktitle = {{ECIR 2020 - 42nd European Conference on IR Research on Advances in Information Retrieval}},
address = {Lisbon, Portugal},
hal_local_reference = {COOLDB},
series = {Advances in Information Retrieval. Proceedings, Part II},
volume = {Lecture Notes in Computer Science},
number = {12036},
pages = {542-549},
year = {2020},
month = apr,
doi = {10.1007/978-3-030-45442-5\_70},
keywords = {Machine learning ; Intelligence artificial ; Species identification ; Biodiversity ; Snake identification ; Species distribution model ; Bird identification ; Plant identification ; Species prediction},
pdf = {https://hal.inrae.fr/hal-02873670/file/Joly2020_Chapter_LifeCLEF2020TeaserBiodiversity.pdf},
hal_id = {hal-02873670},
hal_version = {v1}
}
Sardari, F., Paiement, A., Hannuna, S., & Mirmehdi, M. (2020). VI-Net: View-Invariant Quality of Human Movement Assessment. Sensors. Retrieved from https://hal.science/hal-02934456
@article{sardari:hal-02934456,
title = {{VI-Net: View-Invariant Quality of Human Movement Assessment}},
author = {Sardari, Faegheh and Paiement, Adeline and Hannuna, Sion and Mirmehdi, Majid},
url = {https://hal.science/hal-02934456},
journal = {{Sensors}},
publisher = {{MDPI}},
year = {2020},
pdf = {https://hal.science/hal-02934456/file/sensors-913369.pdf},
hal_id = {hal-02934456},
hal_version = {v1}
}
Chorowski, J., Chen, N., Marxer, R., Dolfing, H. J. G. A., Łańcucki, A., Sanchez, G., … Laurent, A. (2019). Unsupervised Neural Segmentation and Clustering for Unit Discovery in Sequential Data. In NeurIPS 2019 workshop - Perception as generative reasoning - Structure, Causality, Probability. Vancouver, Canada. Retrieved from https://hal.science/hal-02399138
@inproceedings{chorowski:hal-02399138,
title = {{Unsupervised Neural Segmentation and Clustering for Unit Discovery in Sequential Data}},
author = {Chorowski, Jan and Chen, Nanxin and Marxer, Ricard and Dolfing, Hans J G A and Ła{\'n}cucki, Adrian and Sanchez, Guillaume and Alum{\"a}e, Tanel and Laurent, Antoine},
url = {https://hal.science/hal-02399138},
booktitle = {{NeurIPS 2019 workshop - Perception as generative reasoning - Structure, Causality, Probability}},
address = {Vancouver, Canada},
year = {2019},
month = dec,
pdf = {https://hal.science/hal-02399138/file/PGR009.pdf},
hal_id = {hal-02399138},
hal_version = {v1}
}
Djokic, D., Oña, J., Buchan, S., Širović, A., Duque Mesa, E., May-Collado, L., … Sousa-Lima, R. (2019). Building A Dictionary Of Humpback Whale Song Units As A Tool For Assessing Stock Interactions Summary. World marine mammal conference 2019. Retrieved from https://hal.science/hal-02547084
@misc{djokic:hal-02547084,
title = {{Building A Dictionary Of Humpback Whale Song Units As A Tool For Assessing Stock Interactions Summary}},
author = {Djokic, Divna and O{\~n}a, J. and Buchan, Susannah and {\v S}irovi{\'c}, Ana and Duque Mesa, Esteban and May-Collado, Laura and Malige, Franck and Patris, Julie and Castro, C. and Bouchard, B. and Rossi Santos, M. and Pacheco, A. and Garland, Ellen and Marcondes, M. and Venturini, D. and Baumgarten, J. and Padovese, L. and Gon{\c c}alves, M.I. and Sousa-Lima, Renata},
url = {https://hal.science/hal-02547084},
note = {Poster},
howpublished = {{World marine mammal conference 2019}},
year = {2019},
month = dec,
keywords = {song ; humpback whale ; bioacoustics ; stock},
pdf = {https://hal.science/hal-02547084/file/WMM_POSTER_DjokicEtAl.pdf},
hal_id = {hal-02547084},
hal_version = {v1}
}
@article{morfi:hal-02321703,
title = {{NIPS4Bplus: a richly annotated birdsong audio dataset}},
author = {Morfi, Veronica and Bas, Yves and Pamula, Hanna and Glotin, Herv{\'e} and Stowell, Dan},
url = {https://hal.sorbonne-universite.fr/hal-02321703},
journal = {{PeerJ Computer Science}},
publisher = {{PeerJ}},
volume = {5},
pages = {e223},
year = {2019},
month = oct,
doi = {10.7717/peerj-cs.223},
keywords = {Audio dataset ; Bird vocalisations ; Ecosystems ; Ecoacoustics ; Rich annotations ; Bioinformatics ; Audio signal processing ; Bioacoustics},
pdf = {https://hal.sorbonne-universite.fr/hal-02321703/file/peerj-cs-223.pdf},
hal_id = {hal-02321703},
hal_version = {v1}
}
Patris, J., Malige, F., Glotin, H., Asch, M., & Buchan, S. (2019). A standardized method of classifying pulsed sounds and its application to pulse rate measurement of blue whale southeast Pacific song units. Journal of the Acoustical Society of America, 146(4), 2145–2154. https://doi.org/10.1121/1.5126710
@article{patris:hal-02440173,
title = {{A standardized method of classifying pulsed sounds and its application to pulse rate measurement of blue whale southeast Pacific song units}},
author = {Patris, Julie and Malige, Franck and Glotin, Herv{\'e} and Asch, Mark and Buchan, Susannah},
url = {https://hal.science/hal-02440173},
journal = {{Journal of the Acoustical Society of America}},
publisher = {{Acoustical Society of America}},
volume = {146},
number = {4},
pages = {2145-2154},
year = {2019},
month = oct,
doi = {10.1121/1.5126710},
pdf = {https://hal.science/hal-02440173/file/pdf_archiveJASMANvol_146iss_42145_1.pdf},
hal_id = {hal-02440173},
hal_version = {v1}
}
Dassow, A., Marxer, R., Moore, R., & Stowell, D. (2019). Proceedings of the 2nd International Workshop on Vocal Interactivity in-and-between Humans, Animals and Robots (VIHAR 2019). Retrieved from https://hal.science/hal-03609831
@book{dassow:hal-03609831,
title = {{Proceedings of the 2nd International Workshop on Vocal Interactivity in-and-between Humans, Animals and Robots (VIHAR 2019)}},
author = {Dassow, Angela and Marxer, Ricard and Moore, Roger and Stowell, Dan},
url = {https://hal.science/hal-03609831},
year = {2019},
month = sep,
hal_id = {hal-03609831},
hal_version = {v1}
}
Sardari, F., Paiement, A., & Mirmehdi, M. (2019). View-invariant Pose Analysis for Human Movement Assessment from RGB Data. In 20th International Conference on Image Analysis and Processing (ICIAP). Trento, Italy. https://doi.org/10.1007/978-3-030-30645-8_22
@inproceedings{sardari:hal-02171028,
title = {{View-invariant Pose Analysis for Human Movement Assessment from RGB Data}},
author = {Sardari, Faegheh and Paiement, Adeline and Mirmehdi, Majid},
url = {https://hal.science/hal-02171028},
booktitle = {{20th International Conference on Image Analysis and Processing (ICIAP)}},
address = {Trento, Italy},
year = {2019},
month = sep,
doi = {10.1007/978-3-030-30645-8\_22},
pdf = {https://hal.science/hal-02171028/file/ICIAP2019_FS%20%281%29.pdf},
hal_id = {hal-02171028},
hal_version = {v1}
}
Ferrari, M., Marxer, R., Asch, M., & Glotin, H. (2019). Wave Propagation in the Biosonar Organ of sperm whales using a Finite Difference Time Domain method. In VIHAR. Lodon, United Kingdom. Retrieved from https://hal.science/hal-02445408
@inproceedings{ferrari:hal-02445408,
title = {{Wave Propagation in the Biosonar Organ of sperm whales using a Finite Difference Time Domain method}},
author = {Ferrari, Maxence and Marxer, Ricard and Asch, Mark and Glotin, Herv{\'e}},
url = {https://hal.science/hal-02445408},
booktitle = {{VIHAR}},
address = {Lodon, United Kingdom},
year = {2019},
month = aug,
pdf = {https://hal.science/hal-02445408/file/VIHAR_2019.pdf},
hal_id = {hal-02445408},
hal_version = {v1}
}
Poupard, M., Best, P., Schlüter, J., Symonds, H., Spong, P., Lengagne, T., … Glotin, H. (2019). Large-scale unsupervised clustering of Orca vocalizations: a model for describing Orca communication systems. In 2nd International Workshop on Vocal Interactivity in-and-between Humans, Animals and Robots. Londres, United Kingdom. https://doi.org/10.7287/peerj.preprints.27979v1
@inproceedings{poupard:hal-02965872,
title = {{Large-scale unsupervised clustering of Orca vocalizations: a model for describing Orca communication systems}},
author = {Poupard, Marion and Best, Paul and Schl{\"u}ter, Jan and Symonds, Helena and Spong, Paul and Lengagne, Thierry and Soriano, Thierry and Glotin, Herv{\'e}},
url = {https://hal.science/hal-02965872},
booktitle = {{2nd International Workshop on Vocal Interactivity in-and-between Humans, Animals and Robots}},
address = {Londres, United Kingdom},
year = {2019},
month = aug,
doi = {10.7287/peerj.preprints.27979v1},
pdf = {https://hal.science/hal-02965872/file/poupard_best.pdf},
hal_id = {hal-02965872},
hal_version = {v1}
}
Ferrari, M., Glotin, H., Marxer, R., Barchasz, V., Sarano, V., Gies, V., … Sarano, F. (2019). High-frequency Near-field Physeter macrocephalus Monitoring by Stereo-Autoencoder and 3D Model of Sonar Organ. In OCEANS 2019. Marseille, France. Retrieved from https://hal.science/hal-02313898
@inproceedings{ferrari:hal-02313898,
title = {{High-frequency Near-field Physeter macrocephalus Monitoring by Stereo-Autoencoder and 3D Model of Sonar Organ}},
author = {Ferrari, Maxence and Glotin, Herv{\'e} and Marxer, Ricard and Barchasz, Valentin and Sarano, V{\'e}ronique and Gies, Valentin and Asch, Mark and Sarano, Fran{\c c}ois},
url = {https://hal.science/hal-02313898},
booktitle = {{OCEANS 2019}},
address = {Marseille, France},
year = {2019},
month = jun,
keywords = {Long Term Survey ; 3D Tracking ; Tran- sient Analysis ; Weak Signal Detection ; Abyss Monitoring ; Stereo- Autoencoder ; Autoencoder ; FDTD ; Cetacean Survey ; Index Terms-Passive Acoustic Monitoring},
pdf = {https://hal.science/hal-02313898/file/Sarano_OCEAN.pdf},
hal_id = {hal-02313898},
hal_version = {v1}
}
Ferrari, M., Poupard, M., Giraudet, P., Marxer, R., Prévot, J.-M., Soriano, T., & Glotin, H. (2019). Efficient artifacts filter by density-based clustering in long term 3D whale passive acoustic monitoring with five hydrophones fixed under an Autonomous Surface Vehicle. In OCEANS 2019 (p. 39). Marseille, France. https://doi.org/10.1109/OCEANSE.2019.8867416
@inproceedings{ferrari:hal-02313922,
title = {{Efficient artifacts filter by density-based clustering in long term 3D whale passive acoustic monitoring with five hydrophones fixed under an Autonomous Surface Vehicle}},
author = {Ferrari, Maxence and Poupard, Marion and Giraudet, Pascale and Marxer, Ricard and Pr{\'e}vot, Jean-Marc and Soriano, Thierry and Glotin, Herv{\'e}},
url = {https://hal.science/hal-02313922},
booktitle = {{OCEANS 2019}},
address = {Marseille, France},
number = {2},
pages = {39},
year = {2019},
month = jun,
doi = {10.1109/OCEANSE.2019.8867416},
keywords = {Clustering ; DBSCAN ; Weak Signal Detection ; Transient Analysis ; Tortuosity ; Sperm Whale ; Physeter macrocephalus ; Autonomous Laboratory Vehicle ; Drone ; ASV ; Passive Acoustic Monitoring ; Cetacean Survey ; Abyss Monitoring ; 3D Tracking ; Long Term Survey ; Biosonar ; High Sampling Rate ; Clustering},
pdf = {https://hal.science/hal-02313922/file/Sphyrna_OCEAN.pdf},
hal_id = {hal-02313922},
hal_version = {v1}
}
Patris, J., Komatitsch, D., Sepúlveda, M., Santos, M., Glotin, H., Malige, F., … Asch, M. (2019). Mono-hydrophone localization of baleen whales: a study of propagation using a spectral element method applied in Northern Chile. In Oceans 2019. Marseille, France. https://doi.org/10.1109/OCEANSE.2019.8867333
@inproceedings{patris:hal-02440437,
title = {{Mono-hydrophone localization of baleen whales: a study of propagation using a spectral element method applied in Northern Chile}},
author = {Patris, Julie and Komatitsch, Dimitri and Sep{\'u}lveda, Maritza and Santos, Macarena and Glotin, Herv{\'e} and Malige, Franck and Buchan, Susannah and Asch, Mark},
url = {https://hal.science/hal-02440437},
booktitle = {{Oceans 2019}},
address = {Marseille, France},
year = {2019},
month = jun,
doi = {10.1109/OCEANSE.2019.8867333},
keywords = {acoustic propagation ; underwater acoustics ; source localization ; bioacoustics},
pdf = {https://hal.science/hal-02440437/file/Patris.pdf},
hal_id = {hal-02440437},
hal_version = {v1}
}
Poupard, M., Best, P., Schlüter, J., Prévot, J.-M., Symonds, H., Spong, P., & Glotin, H. (2019). Deep Learning for Ethoacoustics of Orcas on three years pentaphonic continuous recording at Orcalab revealing tide, moon and diel effects. In OCEANS. Marseille, France. Retrieved from https://hal.science/hal-02445426
@inproceedings{poupard:hal-02445426,
title = {{Deep Learning for Ethoacoustics of Orcas on three years pentaphonic continuous recording at Orcalab revealing tide, moon and diel effects}},
author = {Poupard, Marion and Best, Paul and Schl{\"u}ter, Jan and Pr{\'e}vot, Jean-Marc and Symonds, Helena and Spong, Paul and Glotin, Herv{\'e}},
url = {https://hal.science/hal-02445426},
booktitle = {{OCEANS}},
address = {Marseille, France},
year = {2019},
month = jun,
keywords = {Ethoacoustics ; Deep Learning ; Convolutional Neural Networks ; Orcas ; Orcinus orca ; Cetaceans ; Bioacoustics ; Environmental factors ; Soundscape ; Big data},
pdf = {https://hal.science/hal-02445426/file/poupard2019_orcalab_ocean.pdf},
hal_id = {hal-02445426},
hal_version = {v1}
}
Roger, V. (2019). Comment adapter les systèmes d’apprentissages modernes pour les données et problèmes en oncologie? In 1st workshop eSanté : Données, Big Data & IA en Oncologie. Toulouse, France. Retrieved from https://hal.science/hal-03003825
@inproceedings{roger:hal-03003825,
title = {{Comment adapter les syst{\`e}mes d'apprentissages modernes pour les donn{\'e}es et probl{\`e}mes en oncologie?}},
author = {Roger, Vincent},
url = {https://hal.science/hal-03003825},
booktitle = {{1st workshop eSant{\'e} : Donn{\'e}es, Big Data \& IA en Oncologie}},
address = {Toulouse, France},
year = {2019},
month = may,
hal_id = {hal-03003825},
hal_version = {v1}
}
Poupard, M., Ferrari, M., Schlüter, J., Marxer, R., Giraudet, P., Barchasz, V., … Glotin, H. (2019). REAL-TIME PASSIVE ACOUSTIC 3D TRACKING OF DEEP DIVING CETACEAN BY SMALL NON-UNIFORM MOBILE SURFACE ANTENNA. In 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Brighton, United Kingdom. Retrieved from https://hal.science/hal-02445414
@inproceedings{poupard:hal-02445414,
title = {{REAL-TIME PASSIVE ACOUSTIC 3D TRACKING OF DEEP DIVING CETACEAN BY SMALL NON-UNIFORM MOBILE SURFACE ANTENNA}},
author = {Poupard, M. and Ferrari, M. and Schl{\"u}ter, J and Marxer, Ricard and Giraudet, P and Barchasz, V and Gies, V. and Pavan, G and Glotin, H.},
url = {https://hal.science/hal-02445414},
booktitle = {{2019 IEEE International Conference on Acoustics, Speech and Signal Processing}},
address = {Brighton, United Kingdom},
year = {2019},
month = may,
keywords = {3D passive acoustic tracking ; ASV ; tortuosity ; Physeter macrocephalus ; sperm whale ; clicks ; biosonar ; embedded real-time system ; high velocity sound card ; small surface array},
pdf = {https://hal.science/hal-02445414/file/poupard2019.pdf},
hal_id = {hal-02445414},
hal_version = {v1}
}
Bouchard, B., Barnagaud, J.-Y., Poupard, M., Glotin, H., Gauffier, P., Torres Ortiz, S., … Aurélie, C. (2019). Behavioural responses of humpback whales to food-related chemical stimuli. PLoS ONE, 14(2), e0212515. https://doi.org/10.1371/journal.pone.0212515
@article{bouchard:hal-04132529,
title = {{Behavioural responses of humpback whales to food-related chemical stimuli}},
author = {Bouchard, Bertrand and Barnagaud, Jean-Yves and Poupard, Marion and Glotin, Herv{\'e} and Gauffier, Pauline and Torres Ortiz, Sara and Lisney, Thomas and Campagna, Sylvie and Rasmussen, Marianne and Aur{\'e}lie, Celerier},
url = {https://hal.science/hal-04132529},
journal = {{PLoS ONE}},
publisher = {{Public Library of Science}},
volume = {14},
number = {2},
pages = {e0212515},
year = {2019},
month = feb,
doi = {10.1371/journal.pone.0212515},
pdf = {https://hal.science/hal-04132529/file/Behavioural%20responses%20of%20humpback%20whales.pdf},
hal_id = {hal-04132529},
hal_version = {v1}
}
Cooke, M., García Lecumberri, M. L., Barker, J., & Marxer, R. (2019). Lexical frequency effects in English and Spanish word misperceptions. Journal of the Acoustical Society of America, 145(2), EL136–EL141. https://doi.org/10.1121/1.5090196
@article{cooke:hal-02065759,
title = {{Lexical frequency effects in English and Spanish word misperceptions}},
author = {Cooke, Martin and Garc{\'i}a Lecumberri, Mar{\'i}a Luisa and Barker, Jon and Marxer, Ricard},
url = {https://hal.science/hal-02065759},
journal = {{Journal of the Acoustical Society of America}},
publisher = {{Acoustical Society of America}},
volume = {145},
number = {2},
pages = {EL136-EL141},
year = {2019},
month = feb,
doi = {10.1121/1.5090196},
pdf = {https://hal.science/hal-02065759/file/cooke.pdf},
hal_id = {hal-02065759},
hal_version = {v1}
}
Joly, A., Goëau, H., Glotin, H., Spampinato, C., Bonnet, P., Vellinga, W.-P., … Müller, H. (2019). Biodiversity Information Retrieval Through Large Scale Content-Based Identification: A Long-Term Evaluation. In N. Ferro & C. Peters (Eds.), Information Retrieval Evaluation in a Changing World: Lessons Learned from 20 Years of CLEF (Vol. 41, pp. 389–413). Springer. https://doi.org/10.1007/978-3-030-22948-1_16
@incollection{joly:hal-02273280,
title = {{Biodiversity Information Retrieval Through Large Scale Content-Based Identification: A Long-Term Evaluation}},
author = {Joly, Alexis and Go{\"e}au, Herv{\'e} and Glotin, Herv{\'e} and Spampinato, Concetto and Bonnet, Pierre and Vellinga, Willem-Pier and Lombardo, Jean-Christophe and Planqu{\'e}, Robert and Palazzo, Simone and M{\"u}ller, Henning},
url = {https://hal.umontpellier.fr/hal-02273280},
note = {AcknowledgementsThe organization of the PlantCLEF task is supported by the French project Floris'Tic (Tela Botanica, INRIA, CIRAD, INRA, IRD) funded in the context of the national investment program PIA. The organization of the BirdCLEF task is supported by the Xeno-Canto foundation for nature sounds as well as the French CNRS project SABIOD.ORG and EADM MADICS, and Floris'Tic. The annotations of some soundscapes were prepared with the late wonderful Lucio Pando at Explorama Lodges, with the support of Pam Bucur, Marie Trone and H. Glotin. The organization of the SeaCLEF task is supported by the Ceta-mada NGO and the French project Floris'Tic.},
booktitle = {{Information Retrieval Evaluation in a Changing World: Lessons Learned from 20 Years of CLEF}},
hal_local_reference = {CoolDB},
editor = {Ferro, Nicola and Peters, Carol},
publisher = {{Springer}},
series = {The Information Retrieval Series},
volume = {41},
pages = {389-413},
year = {2019},
doi = {10.1007/978-3-030-22948-1\_16},
pdf = {https://hal.umontpellier.fr/hal-02273280/file/clef_book_chapter_20_years.pdf},
hal_id = {hal-02273280},
hal_version = {v1}
}
Yordanova, K., Lüdtke, S., Whitehouse, S., Krüger, F., Paiement, A., Mirmehdi, M., … Kirste, T. (2019). Analysing Cooking Behaviour in Home Settings: Towards Health Monitoring. Sensors. Retrieved from https://hal.science/hal-02003387
@article{yordanova:hal-02003387,
title = {{Analysing Cooking Behaviour in Home Settings: Towards Health Monitoring}},
author = {Yordanova, Kristina and L{\"u}dtke, Stefan and Whitehouse, Samuel and Kr{\"u}ger, Frank and Paiement, Adeline and Mirmehdi, Majid and Craddock, Ian and Kirste, Thomas},
url = {https://hal.science/hal-02003387},
journal = {{Sensors}},
publisher = {{MDPI}},
year = {2019},
keywords = {plan recognition ; activity recognition ; behaviour monitoring ; symbolic models ; probabilistic models ; goal recognition ; sensor-based reasoning},
pdf = {https://hal.science/hal-02003387/file/sensors-434245.pdf},
hal_id = {hal-02003387},
hal_version = {v1}
}
Morgan, J., Paiement, A., Seisenberger, M., Williams, J., & Wyner, A. (2018). A Chatbot Framework for the Children’s Legal Centre. In The 31st international conference on Legal Knowledge and Information Systems (JURIX). Groningen, Netherlands. Retrieved from https://hal.science/hal-01878545
@inproceedings{morgan:hal-01878545,
title = {{A Chatbot Framework for the Children's Legal Centre}},
author = {Morgan, Jay and Paiement, Adeline and Seisenberger, Monika and Williams, Jane and Wyner, Adam},
url = {https://hal.science/hal-01878545},
booktitle = {{The 31st international conference on Legal Knowledge and Information Systems (JURIX)}},
address = {Groningen, Netherlands},
series = {JURIX 2018},
year = {2018},
month = dec,
keywords = {Machine Learning ; Natural Language Processing ; Children's Legal Rights ; Recurrent Neural Networks ; Chatbot},
pdf = {https://hal.science/hal-01878545v2/file/JURIXCLCChatbot2018.pdf},
hal_id = {hal-01878545},
hal_version = {v2}
}
Gogate, M., Adeel, A., Marxer, R., Barker, J., & Hussain, A. (2018). DNN Driven Speaker Independent Audio-Visual Mask Estimation for Speech Separation. In Interspeech 2018 (pp. 2723–2727). Hybderabad, India: ISCA. https://doi.org/10.21437/Interspeech.2018-2516
@inproceedings{gogate:hal-01868604,
title = {{DNN Driven Speaker Independent Audio-Visual Mask Estimation for Speech Separation}},
author = {Gogate, Mandar and Adeel, Ahsan and Marxer, Ricard and Barker, Jon and Hussain, Amir},
url = {https://hal.science/hal-01868604},
booktitle = {{Interspeech 2018}},
address = {Hybderabad, India},
publisher = {{ISCA}},
pages = {2723-2727},
year = {2018},
month = sep,
doi = {10.21437/Interspeech.2018-2516},
keywords = {Deep Neural Network ; Binary Mask Estimation ; Speech Separation ; Speech Enhancement},
pdf = {https://hal.science/hal-01868604/file/AVMaskInterspeech18%20%283%29.pdf},
hal_id = {hal-01868604},
hal_version = {v1}
}
Balestriero, R., Cosentino, R., Glotin, H., & Baraniuk, R. (2018). Spline Filters For End-to-End Deep Learning. In 35th International Conference on Machine Learning. stockholm, Sweden. Retrieved from https://hal.science/hal-01879266
@inproceedings{balestriero:hal-01879266,
title = {{Spline Filters For End-to-End Deep Learning}},
author = {Balestriero, Randall and Cosentino, Romain and Glotin, Herv{\'e} and Baraniuk, Richard},
url = {https://hal.science/hal-01879266},
booktitle = {{35th International Conference on Machine Learning}},
address = {stockholm, Sweden},
year = {2018},
month = jul,
keywords = {deep learning ; spline ; wavelet},
pdf = {https://hal.science/hal-01879266/file/icml18_spline_balestriero_Glotinetal.pdf},
hal_id = {hal-01879266},
hal_version = {v1}
}
Kobayashi, H. H., Kudo, H., Glotin, H., Roger, V., Poupard, M., Shimotoku, D., … Sezaki, K. (2018). A Real-Time Streaming and Detection System for Bio-acoustic Ecological Studies after the Fukushima Accident. In Multimedia Tools and Applications for Environmental & Biodiversity Informatics. Retrieved from https://hal.science/hal-01879592
@incollection{kobayashi:hal-01879592,
title = {{A Real-Time Streaming and Detection System for Bio-acoustic Ecological Studies after the Fukushima Accident}},
author = {Kobayashi, Hill Hiroki and Kudo, Hiromi and Glotin, Herv{\'e} and Roger, Vincent and Poupard, Marion and Shimotoku, Daisuk{\'e} and Fujiwara, Akio and Nakamura, Kazuhiko and Saito, Kaoru and Sezaki, Kaoru},
url = {https://hal.science/hal-01879592},
booktitle = {{Multimedia Tools and Applications for Environmental \& Biodiversity Informatics}},
year = {2018},
month = jun,
pdf = {https://hal.science/hal-01879592/file/A%20Real-Time%20Streaming%20and%20Detection%20System%20for%20Bio-acoustic%20Ecological%20Studies%20after%20the%20Fukushima%20Accident_%20Kobayashi%2C%20Kudo%2C%20Glotin%2C%20Roger%2CPoupard%2C%20Shimotoku%2C%20Fujiwara%2C%20Nakamura%2C%20Saito%2CSezaki.pdf},
hal_id = {hal-01879592},
hal_version = {v1}
}
Patris, J., Malige, F., Djokic, D., Sousa-Lima, R., & Glotin, H. (2018). Humpback whale song theme recognition tool. DCLDE 2018. Retrieved from https://hal.science/hal-01868825
@misc{patris:hal-01868825,
title = {{Humpback whale song theme recognition tool}},
author = {Patris, Julie and Malige, Franck and Djokic, D. and Sousa-Lima, Renata and Glotin, Herv{\'e}},
url = {https://hal.science/hal-01868825},
note = {Poster},
howpublished = {{DCLDE 2018}},
year = {2018},
month = jun,
pdf = {https://hal.science/hal-01868825/file/DCLDE_poster_Jorobada.pdf},
hal_id = {hal-01868825},
hal_version = {v1}
}
Patris, J., Komatitsch, D., Asch, M., Buchan, S., Malige, F., & Glotin, H. (2018). Monohydrophone 3D localization of baleen whales. In DCLDE 2018. PARIS, France. Retrieved from https://hal.science/hal-01868824
@inproceedings{patris:hal-01868824,
title = {{Monohydrophone 3D localization of baleen whales}},
author = {Patris, Julie and Komatitsch, Dimitri and Asch, Marc and Buchan, Susannah and Malige, Franck and Glotin, Herv{\'e}},
url = {https://hal.science/hal-01868824},
booktitle = {{DCLDE 2018}},
address = {PARIS, France},
year = {2018},
month = jun,
hal_id = {hal-01868824},
hal_version = {v1}
}
Ferrari, M., Marxer, R., Roger, V., Gies, V., Sarano, F., Asch, M., … Glotin, H. (2018). Sperm whales ultra high frequency near field multichannel analysis. The 8th International Workshop on Detection, Classification, Localization, and Density Estimation (DCLDE). Retrieved from https://hal.science/hal-01881615
@misc{ferrari:hal-01881615,
title = {{Sperm whales ultra high frequency near field multichannel analysis}},
author = {Ferrari, Maxence and Marxer, Ricard and Roger, Vincent and Gies, Valentin and Sarano, Fran{\c c}ois and Asch, Mark and Vitry, Hugues and Homme, Axel Preud' and Heuzey, Ren{\'e} and Sarano, V{\'e}ronique and Glotin, Herv{\'e}},
url = {https://hal.science/hal-01881615},
note = {Poster},
howpublished = {{The 8th International Workshop on Detection, Classification, Localization, and Density Estimation (DCLDE)}},
year = {2018},
month = jun,
pdf = {https://hal.science/hal-01881615/file/Poster_DCLDE.pdf},
hal_id = {hal-01881615},
hal_version = {v1}
}
Malige, F., Patris, J., J., S., Stafford, K. M., Hucke-Gaete, R., Rendell, L., … Glotin, H. (2018). Joint analysis of pulsation and peak frequency : toward a new mathematical model for examining frequency decrease in pulsed blue whale song. In DCLDE 2018. PARIS, France. Retrieved from https://hal.science/hal-01868823
@inproceedings{malige:hal-01868823,
title = {{Joint analysis of pulsation and peak frequency : toward a new mathematical model for examining frequency decrease in pulsed blue whale song}},
author = {Malige, Franck and Patris, Julie and J., Susannah and Stafford, Kathleen M and Hucke-Gaete, R. and Rendell, L. and Neira, Sergio and Glotin, Herv{\'e}},
url = {https://hal.science/hal-01868823},
booktitle = {{DCLDE 2018}},
address = {PARIS, France},
year = {2018},
month = jun,
keywords = {bioacoustic whale songtype frequency decrease},
hal_id = {hal-01868823},
hal_version = {v1}
}
Poupard, M., de Montgolfier, B., Roger, V., Lohani, D., & Glotin, H. (2018). EthoAcoustics : a model based on t-SNE & Clustering, ap-plied on Pantropical spotted dolphin during Whale Watching. 8th International DCLDE (Detection, Classification, Localization, and Density Estimation) Workshop. Retrieved from https://hal.science/hal-01873336
@misc{poupard:hal-01873336,
title = {{EthoAcoustics : a model based on t-SNE \& Clustering, ap-plied on Pantropical spotted dolphin during Whale Watching}},
author = {Poupard, Marion and de Montgolfier, Benjamin and Roger, Vincent and Lohani, Devashish and Glotin, Herv{\'e}},
url = {https://hal.science/hal-01873336},
note = {Poster},
howpublished = {{8th International DCLDE (Detection, Classification, Localization, and Density Estimation) Workshop}},
year = {2018},
month = jun,
pdf = {https://hal.science/hal-01873336/file/EthoAcoustics.pdf},
hal_id = {hal-01873336},
hal_version = {v1}
}
Malige, F., Patris, J., Buchan, S. J., & Glotin, H. (2018). Acoustical analysis of submarine explosions in northern Chile on long terms continuous recordings. DCLDE 2018. Retrieved from https://hal.science/hal-01868827
@misc{malige:hal-01868827,
title = {{Acoustical analysis of submarine explosions in northern Chile on long terms continuous recordings}},
author = {Malige, Franck and Patris, Julie and Buchan, Susannah J and Glotin, Herv{\'e}},
url = {https://hal.science/hal-01868827},
note = {Poster},
howpublished = {{DCLDE 2018}},
year = {2018},
month = jun,
pdf = {https://hal.science/hal-01868827/file/DCLDE_poster_explosions.pdf},
hal_id = {hal-01868827},
hal_version = {v1}
}
Alghamdi, N., Maddock, S., Marxer, R., Barker, J., & Brown, G. (2018). A corpus of audio-visual Lombard speech with frontal and profile views. Journal of the Acoustical Society of America, 143(6), EL523–EL529. https://doi.org/10.1121/1.5042758
@article{alghamdi:hal-01867824,
title = {{A corpus of audio-visual Lombard speech with frontal and profile views}},
author = {Alghamdi, Najwa and Maddock, Steve and Marxer, Ricard and Barker, Jon and Brown, Guy},
url = {https://hal.science/hal-01867824},
journal = {{Journal of the Acoustical Society of America}},
publisher = {{Acoustical Society of America}},
volume = {143},
number = {6},
pages = {EL523-EL529},
year = {2018},
doi = {10.1121/1.5042758},
pdf = {https://hal.science/hal-01867824/file/jasa-el-slash.pdf},
hal_id = {hal-01867824},
hal_version = {v1}
}
Marxer, R., Barker, J., Alghamdi, N., & Maddock, S. (2018). The impact of the Lombard effect on audio and visual speech recognition systems. Speech Communication, 100, 58–68. https://doi.org/10.1016/j.specom.2018.04.006
@article{marxer:hal-01779704,
title = {{The impact of the Lombard effect on audio and visual speech recognition systems}},
author = {Marxer, Ricard and Barker, Jon and Alghamdi, Najwa and Maddock, Steve},
url = {https://hal.science/hal-01779704},
journal = {{Speech Communication}},
publisher = {{Elsevier : North-Holland}},
volume = {100},
pages = {58-68},
year = {2018},
doi = {10.1016/j.specom.2018.04.006},
keywords = {Automatic speech recognition ; Multimodal speech ; Lombard speech ; Intelligibility ; Robust speech processing ; Visual speech},
pdf = {https://hal.science/hal-01779704/file/1-s2.0-S0167639317302674-main.pdf},
hal_id = {hal-01779704},
hal_version = {v1}
}
Dassow, A., Marxer, R., & Moore, R. (2017). Proceedings of the 1st International Workshop on Vocal Interactivity in-and-between Humans, Animals and Robots (VIHAR 2017). Retrieved from https://hal.science/hal-03609819
@book{dassow:hal-03609819,
title = {{Proceedings of the 1st International Workshop on Vocal Interactivity in-and-between Humans, Animals and Robots (VIHAR 2017)}},
author = {Dassow, Angela and Marxer, Ricard and Moore, Roger},
url = {https://hal.science/hal-03609819},
year = {2017},
month = sep,
hal_id = {hal-03609819},
hal_version = {v1}
}
Martin, V., Bruno, E., & Murisasco, E. (2016). Predicting The French Stock Market Using Social Media Analysis. IJVCSN, International Journal of Virtual Communities and Social Networking, 8(15). Retrieved from https://amu.hal.science/hal-01479307
@article{martin:hal-01479307,
title = {{Predicting The French Stock Market Using Social Media Analysis}},
author = {Martin, Vincent and Bruno, Emmanuel and Murisasco, Elisabeth},
url = {https://amu.hal.science/hal-01479307},
note = {http://www.igi-global.com/article/dynamic-social-and-media-content-syndication-for-second-screen/146276},
journal = {{IJVCSN, International Journal of Virtual Communities and Social Networking}},
publisher = {{George Washington University, State University of New York at Plattsburgh}},
volume = {8},
number = {15},
year = {2016},
month = feb,
hal_id = {hal-01479307},
hal_version = {v1}
}
Chollet, G., Amehraye, A., Razik, J., Zouari, L., Khemiri, H., & Mokbel, C. (2010). Spoken Dialogue in Virtual Worlds. In Development of Multimodal Interfaces: Active Listening and Synchrony. Springer. Retrieved from https://hal.science/hal-04094203
@incollection{chollet:hal-04094203,
title = {{Spoken Dialogue in Virtual Worlds}},
author = {Chollet, G{\'e}rard and Amehraye, Asmaa and Razik, Joseph and Zouari, Leila and Khemiri, Houssemeddine and Mokbel, Chafic},
url = {https://hal.science/hal-04094203},
booktitle = {{Development of Multimodal Interfaces: Active Listening and Synchrony}},
publisher = {{Springer}},
year = {2010},
month = oct,
hal_id = {hal-04094203},
hal_version = {v1}
}
Zouari, L., Khemiri, H., Razik, J., Amehraye, A., & Chollet, G. (2009). Reconnaissance de la parole en temps réel pour le dialogue oral. In Traitement et Analyse de l’Information Méthodes et Applications. Hammamet, Tunisia. Retrieved from https://hal.science/hal-04094181
@inproceedings{zouari:hal-04094181,
title = {{Reconnaissance de la parole en temps r{\'e}el pour le dialogue oral}},
author = {Zouari, Leila and Khemiri, Houssemedine and Razik, Joseph and Amehraye, Asmaa and Chollet, G{\'e}rard},
url = {https://hal.science/hal-04094181},
booktitle = {{Traitement et Analyse de l'Information M{\'e}thodes et Applications}},
address = {Hammamet, Tunisia},
year = {2009},
month = aug,
hal_id = {hal-04094181},
hal_version = {v1}
}